
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■競馬予想AIを最短で作る!初心者のための完全マニュアル
https://youtu.be/cBGSam-JR_A
シンプルで実戦的な競馬予想AIの作り方
この記事では「PC-KEIBA Database」のユーザー様を対象に、「競馬予想AIを最短で作る方法」を解説します。
当サイトの記事が増えてきたことで「どこから始めればいいの?」と迷ってしまうパソコン初心者の方もいるかもしれません。そこで今回は、競馬予想AIを最短ルートで構築する方法を、netkeiba主催の予想大会「俺プロ」で最強位に輝いた管理人@PC-KEIBAが、具体的かつ分かりやすく解説します。
「競馬予想AIを作ってみたいけど、プログラミングはまったく分からないし、難しそう…」そんな不安を感じている方も大丈夫。ここで紹介する方法なら、Pythonの勉強すら必要なく、とてもシンプル。学習データを用意して、それをあらかじめ作られたPythonのソースコードに渡すだけ。
必要なのはパソコン1台だけで、すべて無料で実践できるので、初心者の方でも手軽にチャレンジできます。この記事の内容をそのまま実践するだけで大丈夫!面倒なPythonの開発環境の構築も不要です。
それでは、さっそく手順を確認していきましょう!
パソコンを準備する
まずはパソコンを準備しましょう。競馬データを取得するために必要な「JV-Link」と「UmaConn」は、どちらもWindows専用のプログラムなので、今回ご紹介する方法で競馬予想AIを作るにはWindows PCが必須になります。
動作環境のチェック
パソコンを持ってない人は、ネットのフリマとかで手頃な中古のノートパソコンを探してみるのがオススメです。そのとき「JV-Link」の動作環境の最新情報をしっかりチェックして、対応OSに注意してください。
動作環境の最新情報は、次の記事を参考にしてください。
■動作環境のチェック
https://pc-keiba.com/wp/environment/
必要なソフトをインストールする
パソコンが準備できたら、競馬予想AIを作るために必要なソフトをインストールしていきましょう。準備するのはたった4つ!
- PC-KEIBA Database
- サクラエディタ
- A5:SQL Mk-2
- pgAdmin
このシンプルなステップから、あなたの競馬予想AIプロジェクトがスタートします!
PC-KEIBA Databaseのインストール
「PC-KEIBA Database」は、JRAの公式データを使って、PostgreSQLで簡単に競馬データベースを作れるソフトです。SQLを使えば、普通の競馬ソフトでは不可能なデータ集計も自由自在です。セットアップデータ登録で、過去30年分以上のJRA公式競馬データの登録が簡単に終わります。
「TARGET」を利用中の方は、同じJRA-VANのサービスキーを使って「PC-KEIBA Database」も利用できます。
PC-KEIBA Database オンラインマニュアルの「ソフトを使う準備」に書いてある、次の5つの作業を進めてください。
- JV-LinkとUmaConnのインストール
- PostgreSQL のインストール
- PC-KEIBA Database のインストール
- 登録対象データの設定
- セットアップデータを登録する
■PC-KEIBA Database オンラインマニュアル
https://pc-keiba.com/wp/manual-menu/
サクラエディタのインストール
「サクラエディタ」は、Windowsで使える無料のテキストエディタです。ちなみに「テキストエディタ」とは、文章の作成やプログラムの編集など、さまざまな用途に使えるソフトのことです。
他にお気に入りがあればそれで構いませんが、テキストエディタが初めての人にはサクラエディタをオススメします。
サクラエディタのインストールと使い方は、次の記事を参考にしてください。
■サクラエディタのインストールと初期設定
https://pc-keiba.com/wp/sakura-editor-setting/
■サクラエディタで .sql や .py ファイルを開く方法
https://pc-keiba.com/wp/sakura-editor-guide/
A5:SQL Mk-2のインストール
「A5:SQL Mk-2」は、Windowsで使える無料のデータベース管理ツールです。SELECT文の実行や検索結果のファイル出力、テーブル定義の確認に適しています。
A5:SQL Mk-2のインストールは、次の記事を参考にしてください。
■A5:SQL Mk-2のインストールと初期設定
https://pc-keiba.com/wp/a5sqlmk2-setting/
pgAdminのインストール
「pgAdmin」は、PostgreSQL専用の公式無料データベース管理ツールです。テーブルの作成や、プロシージャの実行を行うならこちらが便利です。エラーが発生した際に行番号を示してくれるため、問題の特定がスムーズにできて、作業効率が大幅にアップします。
「A5:SQL Mk-2」と「pgAdmin」は、それぞれ得意なことが違うため、目的に応じて使い分けるのがベストです。
pgAdminのインストールは、次の記事を参考にしてください。
■pgAdminのインストールと使い方
https://pc-keiba.com/wp/pgadmin/
Pythonをインストールする
必要なソフトがインストールできたら、自分だけのオリジナル学習データを使ってAIに競馬予想させるために、プログラミング言語の「Python」をインストールします。
「AI(人工知能)」とは、大量のデータからパターンやルールを学習して、その結果をもとに未来の結果を予測する賢いプログラムのことです。
LightGBMによるAI競馬予想の場合
初心者や、まずシンプルなモデルで予測精度を確認したい場合は「LightGBM」がオススメです。競馬予想データの多くはテーブル形式の構造化データなので「LightGBM」の得意分野です。
- Python
- pandas
- scikit-learn
- LightGBM
- Matplotlib
次の記事の「Pythonのインストール」と「ライブラリのインストール」の章を参考に、上記1~5のPythonおよび必要なライブラリをセットアップしてください。
■LightGBMによるAI競馬予想(準備編)
https://pc-keiba.com/wp/lightgbm/
KerasによるAI競馬予想の場合
より高度な予測を目指したい、または非線形で複雑な関係性を学習したい場合は「Keras」を使うのが適しています。競馬予想では、まず「LightGBM」で基本的なモデルを作り、その後に「Keras」でさらに高度な分析を試すという流れも効率的です。
- Python
- pandas
- scikit-learn
- TensorFlow
- Keras
次の記事の「Pythonのインストール」と「ライブラリのインストール」の章を参考に、上記1~5のPythonおよび必要なライブラリをセットアップしてください。
■Kerasで実現するディープラーニングによるAI競馬予想(準備編)
https://pc-keiba.com/wp/keras/
データ仕様書を読む
この記事で紹介する方法なら、競馬予想AIを作るのに必要なスキルはたった1つ、それはSQLを書けることだけです。これさえできれば、データを自由に扱えるようになります。
とはいえ、SQLを書くには、データベースにどんなデータがあるのかを知っておくことが大切です。とはいっても、データ仕様書をすべて暗記する必要はありません。「こんなデータがあるんだな」と、ざっと目を通しておくだけでOK。実際にSQLを書くときに、必要な部分を仕様書で確認すれば十分です。
それでは、次の2つの仕様書に目を通してみましょう!
JV-Data 仕様書
「JV-Data」は、JRA-VANが提供するJRA公式の競馬データです。初月は無料で利用できるため、競馬予想AIを作るための過去データを無料で入手できます。
仕様書はPDF版とExcel版の2種類があるので、好きなほうを選べますが、個人的にはPDF版がオススメです。
■JV-Data 仕様書 (JRA-VANのサイトに移動します)
https://jra-van.jp/dlb/sdv/sdk.html
JV-Dataは、スクレイピングでは取得できない貴重な情報を提供してくれる頼れるデータサービスです。例えば、過去数十年分のレース詳細、競走馬マスタのデータはもちろん、レース当日にならないと分からない馬体重や馬場状態といった速報系データまで幅広くカバー。
ちなみに「PC-KEIBA Database」は、このJV-Dataの仕様書を基準に全機能を設計しています。
PC-KEIBAテーブル定義書
SQLを書くために必要な情報が、ここにすべて載ってます。例えば、JV-Dataのデータがデータベース内のどのテーブルに保存されているのか、各項目の名前やデータの種類(データ型)は何なのか、といった基本情報を確認できます。
■PC-KEIBAテーブル定義書
PC-KEIBAテーブル定義書.zip (Excel版)
ダウンロードしたzipファイルは、右クリック→「すべて展開」で解凍できます。
Excelを持ってない人は「A5:SQL Mk-2」で見るだけでもOK。
正直、このテーブル定義書は必要なくて、個人的には「A5:SQL Mk-2」の「カラム」タブで項目の定義を確認するだけで十分だと思います。
機械学習の基礎知識を得る
競馬予想AIを作る手順
「LightGBM」または「Keras」を使って競馬予想AIを作るための、大まかな作業手順は次のとおりです。
- データの分析方法を決める
- 学習データを作る
- 機械学習モデルを作る
- モデルを評価する
- 予測(予想)させる
具体的な手順については、次の記事の「競馬予想AIを作る手順」の章で詳しく解説しているので、1~5の流れをしっかり確認しながら進めてみてください。
■LightGBMによるAI競馬予想(準備編)
https://pc-keiba.com/wp/lightgbm/
■Kerasで実現するディープラーニングによるAI競馬予想(準備編)
https://pc-keiba.com/wp/keras/
データの分析方法について
データの分析方法に「これが最強」という決まりやルールはありません。目的や、どんな分野でAIを活用したいかによって、適した手法は変わります。競馬予想の場合、例えば、
- 3連複の場合は二値分類
- 3連単の場合は多クラス分類
- タイム指数を扱うなら回帰分析
といったように、作りたいAIの得意分野や目標に合わせて選ぶのがポイントです。
初心者の方は、あれこれ深く考えたり悩んだりせず、まずは気軽な気持ちで何か1つ試してみることから始めましょう。
SELECT文をマスターする
Pythonの勉強なんて必要なし!努力と時間の無駄です。SQLのSELECT文さえマスターすれば、競馬予想AIなんて本当に誰でも簡単に作れます。
まずは、この記事を見ながら必要なソフトをインストールし、実際にSQLを書いて試してみましょう。ただ眺めているだけでは何も始まりません。SQLを書いて実行し、エラーが出たら修正する。この繰り返しこそが、最短で上達するコツです。勉強や調べるのが面倒だからと後回しにしていては、いつまでも初心者のままです。
今の時代、ググればほとんどの問題は解決できるし、「ChatGPT」を使えばSQLの書き方もサクッと教えてくれて、しかも丁寧な解説まで付いてきます。これでSQLを学ばない理由なんてありますか?迷う必要は一切ありません。それに、競馬がもっと楽しくなって、ITスキルまで身につくなんて、一石二鳥どころか最高じゃないですか!
次の章では「学習データの作り方」を解説しますが、実際に手を動かしてSQLを書きながら学ぶことで、効率よく習得できます。「SQLを実行する手順」と「SELECT文の基本」については、次の記事で詳しく解説しているので、ぜひチェックしてみてください!
■SQLを実行する手順
https://pc-keiba.com/wp/to-execute-sql/
■SELECT文の基本
https://pc-keiba.com/wp/sql-basics/
学習データを作る
学習データがAIの品質を左右する
競馬予想AIを作る上で、鍵となるのは学習データの構築です。学習データさえ用意できれば、競馬予想AIはほぼ完成したも同然。まさに、学習データがAIの品質を左右すると言っても過言ではありません。
初心者には少しハードルが高く感じるかもしれませんが、実は意外とシンプルです。独自に集計したデータをテーブルに保存するだけで、学習データは簡単に作れます。
例えば、1走前の入線順位ごとに回収率を集計し、その結果をテーブルに保存して説明変数として使う、といった方法があります。このような工夫で、効率的に学習データを整えることができます。
説明変数のアイデアを考えよう
機械学習では「特徴量」という言葉がよく使われますが、「特徴量」と「説明変数」はどちらも予測に使うデータという点で、ほぼ同じ意味と考えて大丈夫です!
競馬を観戦しながらひらめきを探したり、世の中にある馬券必勝法のアイデアを参考にしつつ、AIに与える説明変数を考えてみましょう。工夫次第でいろいろな視点からデータを作れます。
例えば、こんなアイデアがあります。
- コンピ指数を説明変数に使ってみる
- 1走前の入線順位ごとにデータを集計してみる
- 1走前の単勝人気順ごとにデータを集計してみる
- 血統を競馬場や距離ごとに集計して、特徴を探してみる
- 出走馬の馬体重を相対的に比較して集計してみる
アイデアは無限大です。さまざまな視点から試してみて、どんなデータが予測に役立つか探ってみてください。
競馬予想には、説明変数を複数用意する必要があります。だって、「タイム」や「血統」みたいな1つの要素だけでレースの結果が決まるなんて、ありえないですよね?
集計結果を出すSELECT文を書いてみる
それでは、そのアイデアを実際にSQLで集計してみましょう。そして、集計した勝率や単勝回収率が実用レベルに達しているかどうかを検証します。集計するのは、複勝率でも複勝回収率でも構いません。
例えば、1走前の入線順位だけを基準に集計しても、期待したほど良い結果が得られないこともあります。そんなときは、1走前の入線順位に加えて、1走前の脚質データなどを組み合わせてデータをより具体化し、的中率や回収率をさらに絞り込む方法を試してみるのがオススメです。
理想的なデータは、条件がシンプルでありながら、的中率や回収率が優秀なものです。ここで言う「シンプル」とは、少ない条件で多くの馬が該当するデータのことです。
例えば、1つの項目だけで集計されたデータがその代表例です。条件がシンプルであればあるほど該当する馬が増え、予想を組み立てる際に活用しやすくなるからです。
このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
/* 入線順位・1走前 */
SELECT
count(*) AS record_count
, sum(ap.chakukaisu_1) / count(*) AS shoritsu -- 勝率
, sum(ap.haraimodoshi_tansho) / (count(*) * 100) AS kaishuritsu_tansho -- 単勝回収率
, k1.group_1 AS track_code
, k2.group_1 AS kako1_track_code
, se1.nyusen_juni AS kako1_nyusen_juni
FROM
jvd_ra ra
INNER JOIN
jvd_se se
ON se.kaisai_nen = ra.kaisai_nen
AND se.kaisai_tsukihi = ra.kaisai_tsukihi
AND se.keibajo_code = ra.keibajo_code
AND se.race_bango = ra.race_bango
INNER JOIN
apd_se_jv ap
ON ap.kaisai_nen = se.kaisai_nen
AND ap.kaisai_tsukihi = se.kaisai_tsukihi
AND ap.keibajo_code = se.keibajo_code
AND ap.race_bango = se.race_bango
AND ap.umaban = se.umaban
INNER JOIN
jvd_ra ra1
ON ra1.kaisai_nen = ap.kako1_kaisai_nen
AND ra1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND ra1.keibajo_code = ap.kako1_keibajo_code
AND ra1.race_bango = ap.kako1_race_bango
INNER JOIN
jvd_se se1
ON se1.kaisai_nen = ap.kako1_kaisai_nen
AND se1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND se1.keibajo_code = ap.kako1_keibajo_code
AND se1.race_bango = ap.kako1_race_bango
AND se1.ketto_toroku_bango = ap.ketto_toroku_bango
INNER JOIN
myd_track_code k1
ON k1.track_code = ra.track_code
INNER JOIN
myd_track_code k2
ON k2.track_code = ra1.track_code
WHERE 1 = 1
AND ra.data_kubun = '7'
AND ra.kaisai_nen || ra.kaisai_tsukihi >= '20070101'
AND ra.kaisai_nen || ra.kaisai_tsukihi <= '20241231'
AND ra1.data_kubun = '7'
AND se.ijo_kubun_code NOT IN ('1', '2', '3')
AND se1.nyusen_juni > '00'
GROUP BY
k1.group_1 -- track_code
, k2.group_1 -- kako1_track_code
, se1.nyusen_juni -- kako1_nyusen_juni
ORDER BY
k1.group_1 ASC -- track_code
, k2.group_1 ASC -- kako1_track_code
, se1.nyusen_juni ASC -- kako1_nyusen_juniここでは、JV-Dataの「トラックコード」を、芝・芝直線・ダート・障害の4種類に分類できるように、独自のコード変換テーブル(myd_track_code)を作りました。
このSQLで、このページと同じ検索結果を得るには、
・馬毎払戻過去走データ登録
が必要です。
表計算ソフトのExcelで表示するとこんなデータになります。
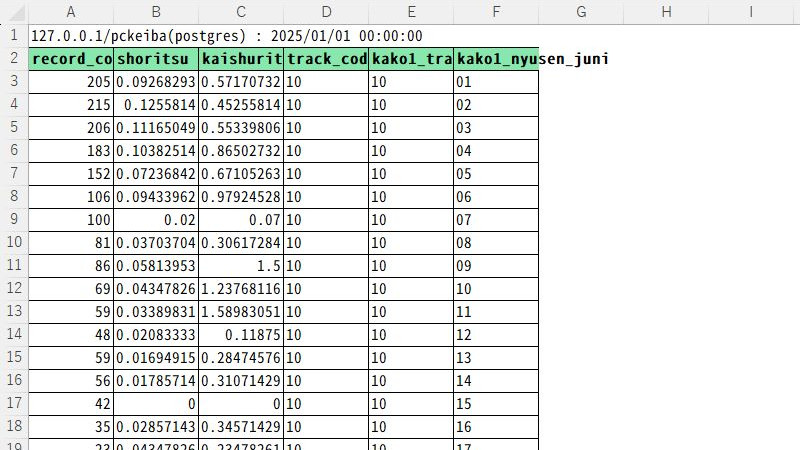
左から、
- レコード数
- 勝率
- 単勝回収率
- トラックコード
- トラックコード・1走前
- 入線順位・1走前
集計データは自由に設計できますが、すべての集計データに共通する項目(どの集計データにも含まれる項目)は、先頭に統一して配置するのがオススメです。そうすることで、見やすくなり、管理や修正もスムーズに行えます。
例えば、1着馬を予測する競馬予想AIを作る場合は、勝率と単勝回収率を項目として設定します。将来的に3連複や3連単まで対応するAIを視野に入れるなら、ここに複勝率や複勝回収率も加えておくと、後々の拡張がスムーズになります。
今回はサンプルとして、勝率と単勝回収率の2つだけを使って進めていきます。
集計結果を保存するテーブルを設計する
集計データの勝率や回収率に納得したら、次のステップは集計結果を出すSELECT文の項目に一致するテーブルを設計することです。と言っても、大げさなものではありません。「CREATE TABLE」のSQL文をサクラエディタに書くだけでも、十分立派な設計です。
CREATE TABLE文の書き方は、既存のテーブルのSQLをコピーすれば簡単に作れます。SQLの構文は完成しているから、テキストエディタでテーブル名を置換して項目名を編集すれば良いだけです。
その際には、「pgAdmin」を使うのがオススメです。pgAdminならコメントのSQLまで一緒にコピーできるので、とても便利です。ただし、コピーして作ったCREATE TABLE文にミスがないか十分に注意してください。コピー元のテーブルにミスが反映されてしまうリスクがあるためです。
例えば、1走前の入線順位をキーにして勝率と単勝回収率を集計する場合、次のようなテーブルが考えられます。
このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
-- Table: public.myd_kako1_nyusen_juni
-- DROP TABLE IF EXISTS public.myd_kako1_nyusen_juni;
CREATE TABLE IF NOT EXISTS public.myd_kako1_nyusen_juni
(
record_count numeric,
shoritsu numeric,
kaishuritsu_tansho numeric,
track_code character varying(2) COLLATE pg_catalog."default" NOT NULL,
kako1_track_code character varying(2) COLLATE pg_catalog."default" NOT NULL,
kako1_nyusen_juni character varying(2) COLLATE pg_catalog."default" NOT NULL,
CONSTRAINT myd_kako1_nyusen_juni_pk PRIMARY KEY (track_code, kako1_track_code, kako1_nyusen_juni)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.myd_kako1_nyusen_juni
OWNER to postgres;
COMMENT ON TABLE public.myd_kako1_nyusen_juni
IS '入線順位・1走前';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.record_count
IS 'レコード数';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.shoritsu
IS '勝率';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.kaishuritsu_tansho
IS '単勝回収率';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.track_code
IS 'トラックコード';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.kako1_track_code
IS 'トラックコード・1走前';
COMMENT ON COLUMN public.myd_kako1_nyusen_juni.kako1_nyusen_juni
IS '入線順位・1走前';説明変数用のテーブルをいくつか作ってパターンが決まれば、作業はどんどん簡単になります。それらをコピーして少し手を加えるだけで、効率よく説明変数を増やすことができるからです。
INSERT…SELECTでテーブルにデータを保存する
「CREATE TABLE」を実行してテーブルを作ったら、次は「INSERT…SELECT」を使って集計データをそのテーブルに保存しましょう。
「INSERT…SELECT」とは、SELECT文の実行結果をINSERT文でテーブルに登録するSQL文のことです。構文は、SELECT文の先頭に「INSERT INTO テーブル名」を追加するだけ。この便利な方法を使えば、とても簡単にデータを保存できます。
このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
/* 入線順位・1走前 */
INSERT INTO
myd_kako1_nyusen_juni
SELECT
count(*) AS record_count
, sum(ap.chakukaisu_1) / count(*) AS shoritsu -- 勝率
, sum(ap.haraimodoshi_tansho) / (count(*) * 100) AS kaishuritsu_tansho -- 単勝回収率
, k1.group_1 AS track_code
, k2.group_1 AS kako1_track_code
, se1.nyusen_juni AS kako1_nyusen_juni
FROM
jvd_ra ra
INNER JOIN
jvd_se se
ON se.kaisai_nen = ra.kaisai_nen
AND se.kaisai_tsukihi = ra.kaisai_tsukihi
AND se.keibajo_code = ra.keibajo_code
AND se.race_bango = ra.race_bango
INNER JOIN
apd_se_jv ap
ON ap.kaisai_nen = se.kaisai_nen
AND ap.kaisai_tsukihi = se.kaisai_tsukihi
AND ap.keibajo_code = se.keibajo_code
AND ap.race_bango = se.race_bango
AND ap.umaban = se.umaban
INNER JOIN
jvd_ra ra1
ON ra1.kaisai_nen = ap.kako1_kaisai_nen
AND ra1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND ra1.keibajo_code = ap.kako1_keibajo_code
AND ra1.race_bango = ap.kako1_race_bango
INNER JOIN
jvd_se se1
ON se1.kaisai_nen = ap.kako1_kaisai_nen
AND se1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND se1.keibajo_code = ap.kako1_keibajo_code
AND se1.race_bango = ap.kako1_race_bango
AND se1.ketto_toroku_bango = ap.ketto_toroku_bango
INNER JOIN
myd_track_code k1
ON k1.track_code = ra.track_code
INNER JOIN
myd_track_code k2
ON k2.track_code = ra1.track_code
WHERE 1 = 1
AND ra.data_kubun = '7'
AND ra.kaisai_nen || ra.kaisai_tsukihi >= '20070101'
AND ra.kaisai_nen || ra.kaisai_tsukihi <= '20241231'
AND ra1.data_kubun = '7'
AND se.ijo_kubun_code NOT IN ('1', '2', '3')
AND se1.nyusen_juni > '00'
GROUP BY
k1.group_1 -- track_code
, k2.group_1 -- kako1_track_code
, se1.nyusen_juni -- kako1_nyusen_juni
ORDER BY
k1.group_1 ASC -- track_code
, k2.group_1 ASC -- kako1_track_code
, se1.nyusen_juni ASC -- kako1_nyusen_juni説明変数とアイデアの出力を繰り返す
学習データの作成は、
- 説明変数のアイデアを考えよう
- 集計結果を出すSELECT文を書いてみる
- 保存するテーブルを設計する
- INSERT…SELECTでテーブルにデータを保存する
このプロセスを繰り返すだけです。事前にテーブルに保存しておくこの方法なら、説明変数の集計が複雑で時間がかかる場合でも、効率よく学習データを準備できます。さらに、説明変数がどれだけ増えても同じ仕組みで対応できるので、とても安心です。
SELECT文でファイル出力
説明変数が揃ったら、それらを組み合わせて学習データを作成するSELECT文を書いてみましょう。複数の説明変数を含むテーブルを結合し、AIが学習できる形に整えます。
ここでは、次の3つの説明変数と、目的変数を出力することにします。
- 入線順位・1走前
- 単勝人気順・1走前
- タイム差・1走前
/* SELECT文でファイル出力 */
SELECT
round(x1.shoritsu * 100) AS kako1_nyusen_juni
, round(x2.shoritsu * 100) AS kako1_tansho_ninkijun
, round(x2.shoritsu * 100) AS kako1_time_sa
, CASE WHEN se.nyusen_juni = '01' THEN 1 ELSE 0 END AS target -- 目的変数
FROM
jvd_ra ra
INNER JOIN
jvd_se se
ON se.kaisai_nen = ra.kaisai_nen
AND se.kaisai_tsukihi = ra.kaisai_tsukihi
AND se.keibajo_code = ra.keibajo_code
AND se.race_bango = ra.race_bango
INNER JOIN
apd_se_jv ap
ON ap.kaisai_nen = se.kaisai_nen
AND ap.kaisai_tsukihi = se.kaisai_tsukihi
AND ap.keibajo_code = se.keibajo_code
AND ap.race_bango = se.race_bango
AND ap.umaban = se.umaban
INNER JOIN
jvd_ra ra1
ON ra1.kaisai_nen = ap.kako1_kaisai_nen
AND ra1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND ra1.keibajo_code = ap.kako1_keibajo_code
AND ra1.race_bango = ap.kako1_race_bango
INNER JOIN
jvd_se se1
ON se1.kaisai_nen = ap.kako1_kaisai_nen
AND se1.kaisai_tsukihi = ap.kako1_kaisai_tsukihi
AND se1.keibajo_code = ap.kako1_keibajo_code
AND se1.race_bango = ap.kako1_race_bango
AND se1.ketto_toroku_bango = ap.ketto_toroku_bango
INNER JOIN
myd_track_code k1
ON k1.track_code = ra.track_code
INNER JOIN
myd_track_code k2
ON k2.track_code = ra1.track_code
INNER JOIN
myd_kako1_nyusen_juni x1
ON x1.track_code = k1.group_1
AND x1.kako1_track_code = k2.group_1
AND x1.kako1_nyusen_juni = se1.nyusen_juni
INNER JOIN
myd_kako1_tansho_ninkijun x2
ON x2.track_code = k1.group_1
AND x2.kako1_track_code = k2.group_1
AND x2.kako1_tansho_ninkijun = se1.tansho_ninkijun
INNER JOIN
myd_kako1_time_sa x3
ON x3.track_code = k1.group_1
AND x3.kako1_track_code = k2.group_1
AND x3.kako1_time_sa = se1.time_sa
WHERE 1 = 1
AND ra.data_kubun = '7'
AND ra.kaisai_nen || ra.kaisai_tsukihi >= '20070101'
AND ra.kaisai_nen || ra.kaisai_tsukihi <= '20241231'
AND se.ijo_kubun_code NOT IN ('1', '2', '3')このSELECT文を「A5:SQLMk-2」で実行すれば、結果をそのまま簡単にファイル出力できるため、学習データの準備がスムーズに進みます。これで、AIの学習データがひとまず完成です!
まとめ
今回ご紹介した方法は、あくまで一例にすぎません。競馬予想AIの作り方には、人それぞれさまざまなアプローチがあります。そして、これからあなた自身が新しいアイデアを生み出し、さらなる可能性を広げていくことでしょう。プログラミングの可能性には限界がありません。自由に工夫しながら、自分だけのオリジナル競馬予想AI作りを存分に楽しんでください!
今回の記事では、プログラミングの知識がなくても、競馬予想AIを簡単に始められることが分かりました。やることはシンプルで、学習データを用意して、あらかじめ作られたPythonのソースコードに渡すだけ。それだけで、新しい競馬予想の可能性がきっと広がるはずです。
競馬予想AIを最短で作る方法
最後に、競馬予想AIを最短ルートで作る方法をおさらいしておきましよう。これらを順に実践すれば、競馬予想AIの完成が見えてきます!
- パソコンを準備する
- 必要なソフトをインストールする
- Pythonをインストールする
- データ仕様書を読む
- 機械学習の基礎知識を得る
- SELECT文をマスターする
- 学習データを作る
さあ、あなたも競馬予想AI作りに挑戦してみましょう!わからなくなったときは、この記事を何度でも読み返せばきっと大丈夫です!
