
Optunaで競馬予想AIモデルをチューニング
Optuna
「Optuna(オプチュナ)」は、最適なハイパーパラメータを見つけるためのPythonライブラリです。オープンソースとして提供されており、ベイズ最適化アルゴリズムを実装しています。Optunaは、東京大学発のAIベンチャーによって開発されました。Optunaを利用することで、複雑なチューニングを手軽に行い、短時間で高性能な機械学習モデルを作ることができます。
LightGBM Tuner
Optunaの拡張機能である「LightGBM Tuner」は、ハイパーパラメータを自動調整してくれるLightGBM専用のモジュールです。重要なハイパーパラメータを優先的に調整し、探索範囲を効率的に絞り込みます。これにより、機械学習モデルの性能を向上させることが可能です。また、ベンチマークテストではLightGBM Tunerが他の手法よりも優れた結果を示しました。
LightGBM Tunerが対応するデータの分析方法
LightGBM Tunerが対応するデータの分析方法と評価指標は、次のとおりです。
二値分類(binary)
- 正答率(binary_error)
- 交差エントロピー(binary_logloss)
多クラス分類(multiclass)
- 正答率(multi_error)
- ソフトマックス関数(multi_logloss)
回帰分析(regression)
- 二乗平均平方根誤差(rmse)
- 平均絶対誤差(mae)
- 平均二乗誤差(mse)
Optunaのインストール
Optunaの拡張機能である「LightGBM Tuner」を使うには、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。
py -m pip install optunapy -m pip install optuna-integrationコマンドプロンプトの使い方は、以下の記事を参考にしてください。
■LightGBMによるAI競馬予想(準備編)
https://pc-keiba.com/wp/lightgbm/
LightGBM Tunerの使い方
LightGBM Tunerを使うには、既存のソースコードに数行の修正を加えるだけでOKです。ここでは、「二値分類」の記事で使ったソースコードを例に説明します。
・多クラス分類(multiclass)
・回帰分析(regression)
の場合も同じです。適宜、読み替えてください。
学習用ソースコード (LightGBM Tuner Ver.)
以下が、LightGBM Tunerバージョンの「二値分類」で学習するPythonのソースコードです。この学習用ソースコードのファイル名は「binary_train_tuning.py」とします。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、この記事の最後の、有料会員限定のダウンロードリンクからも、ファイルをダウンロードできます。
import pandas as pd
import numpy as np
import optuna.integration.lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# CSVファイル読み込み
in_file_name = 'binary_train.csv'
df = pd.read_csv(in_file_name, encoding='SHIFT_JIS')
# 説明変数(x)と目的変数(y)を設定
target = 'target'
x = df.drop(target, axis=1).values # y以外の特徴量
y = df[target].values
# 説明変数の項目名を取得
feature = list(df.drop(target, axis=1).columns)
# 訓練データとテストデータを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error' # 評価指標 : 正答率
}
# モデルの学習
train_set = lgb.Dataset(x_train, y_train)
valid_sets = lgb.Dataset(x_test, y_test, reference=train_set)
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets)
# モデルをファイルに保存
model.save_model('binary_model.txt')
# ハイパーパラメータをファイルに保存
best_params = model.params
with open('best_params.csv', mode='w') as f:
f.writelines('\n'.join(str(key) + ',' + str(value) for key, value in best_params.items()))
# テストデータの予測
y_prob = model.predict(x_test)
y_pred = np.where(y_prob < 0.5, 0, 1)
# 評価指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print('正解率 = ', accuracy)
print('適合率 = ', precision)
print('再現率 = ', recall)
# 特徴量重要度
importance = np.array(model.feature_importance())
df = pd.DataFrame({'feature':feature, 'importance':importance})
df = df.sort_values('importance', ascending=True)
n = len(df) # 説明変数の項目数を取得
values = df['importance'].values
plt.barh(range(n), values)
values = df['feature'].values
plt.yticks(np.arange(n), values) # x, y軸の設定
plt.savefig('binary_train.png', bbox_inches='tight', dpi=500)
plt.show()修正したソースコード
■修正前
import lightgbm as lgb■修正後
import optuna.integration.lightgbm as lgb追加したソースコード
# ハイパーパラメータをファイルに保存
best_params = model.params
with open('best_params.csv', mode='w') as f:
f.writelines('\n'.join(str(key) + ',' + str(value) for key, value in best_params.items()))ハイパーパラメータをファイルに保存する必要がなければ、import文の修正だけで、ベストのパラメータで、今までどおりモデルを保存できます。
こんなに簡単なのに「二値分類」の記事とソースコードを分けた理由は、次の2つです。
- LightGBM Tunerは処理に時間がかかる
- すべてのユーザーがLightGBM Tunerを必要としているとは限らない
LightGBM Tunerの実行
では、「二値分類」の記事で使った同じ学習データを用いて、LightGBM Tunerでハイパーパラメータの自動調整を行い、その結果を比較してみましょう。
今回の例では、Cドライブの直下に「pckeiba」というフォルダを作って、
- 学習データ(binary_train.csv)
- 学習用ソースコード(binary_train_tuning.py)
2つのファイルを置きます。こういう状態です。
学習データの作り方は、以下の記事を参考にしてください。
■LightGBMによるAI競馬予想(二値分類)
https://pc-keiba.com/wp/binary/
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。
cd C:\pckeibapython binary_train_tuning.pyLightGBMが学習を開始します。処理が終わると評価指標を表示します。
実行時間は約10分かかりました。今回は、自動調整したハイパーパラメータの内容を「best_params.csv」に保存しています。
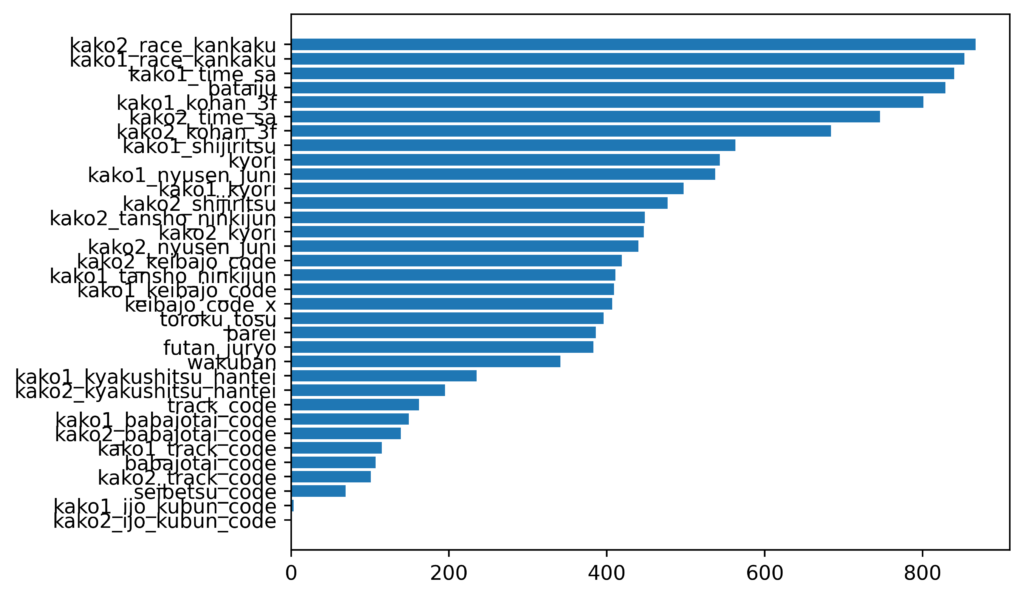
特徴量重要度
チューニング後は、必要な特徴量とそうでないものが明確に分かれたように感じます。
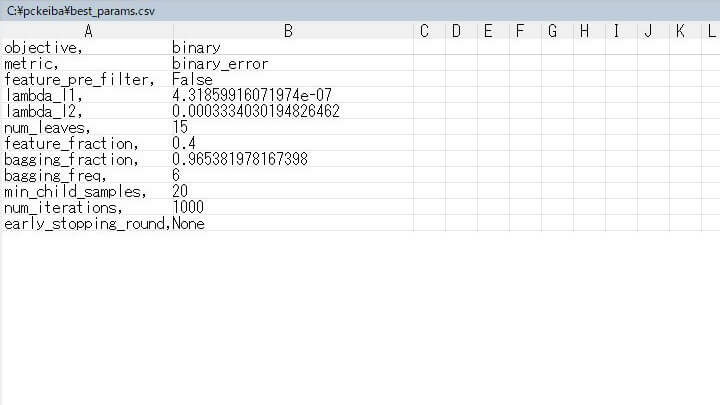
best params
チューニング後のハイパーパラメータは、次のようになりました。
各ハイパーパラメータの詳細については、以下の記事を参考にしてください。
■LightGBMによるAI競馬予想(チューニング編)
https://pc-keiba.com/wp/lightgbm-tuning/
評価指標の比較
チューニング前後の評価指標を比較した結果は、次の通りです。
チューニング前
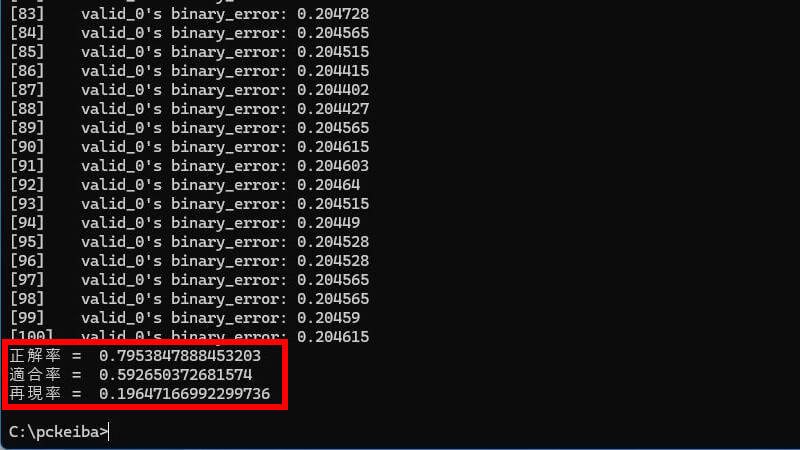
チューニング後
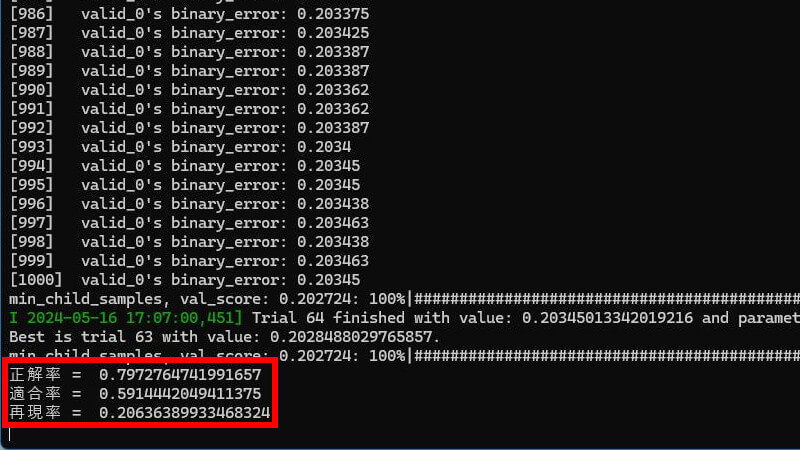
「再現率」がわずかに向上しました。+1%
これがハイパーパラメータチューニングの限界だと仮定すれば、あとは学習データの改善に専念すればOKということです。
注意すべき点は、LightGBM Tunerが提示するbest paramsが常に完璧とは限らないということです。それでも、ハイパーパラメータの意味がよく分からずにデフォルト値を使うよりは、はるかに良い結果が得られるでしょう。
Optunaの話は以上です。「PC-KEIBA Database」で思う存分、AI競馬予想を楽しんでください!
