
LightGBMチューニングの知識
「PC-KEIBA Database」と「LightGBM」を使って、優れたAI競馬予想を作るために、最低限必要なチューニング方法をまとめました。チューニングを習得するためには、以下の2つの概念を理解する必要があるので、まずこれらを説明します。
- 決定木
- 過学習
決定木
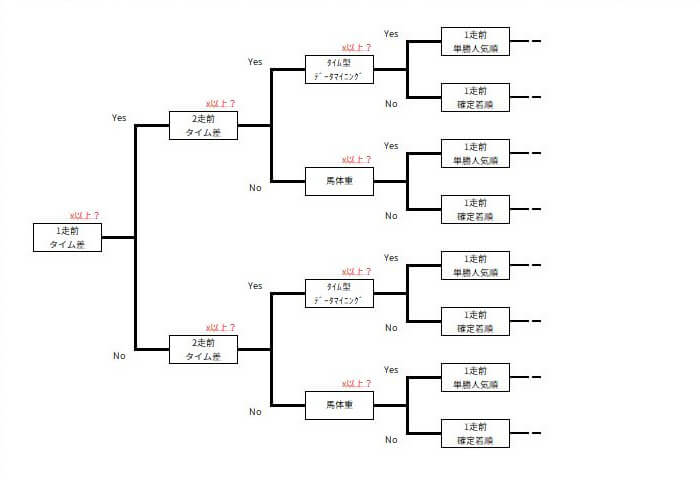
「決定木(けっていぎ)」は「Yes/No」の質問を連続的に行い、データを効率よく整理して目的の結果に導く方法です。これは、LightGBMアルゴリズムの核でもあります。
例えば、競馬予想の場合、決定木は異なる属性(例:レース成績、馬体重など)に関する質問を通じて、レース結果を予測します。優れた決定木を構築することで、予測の精度が向上し、レース結果をより正確に予測できるようになります。
過学習
「過学習(かがくしゅう)」とは、機械学習モデルが学習データを過剰に学習しすぎて、未知のデータに対応できなくなる現象を指します。この問題を解決することは、予測精度を向上させるために非常に重要な課題です。
学習データをチューニング
まず、こいつが先。役に立たない学習データを使ってたらLightGBMのハイパーパラメータをチューニングしても意味がない(笑)
学習データを増やす
データ分析の世界では一般的に、データが多いほど信頼性が高まります。しかし、競馬の場合はルールや条件が変わることがあるため、古すぎるデータを使わないように気を付けましょう。データの内容によっては問題ありませんが、注意が必要です。
データクレンジングする
データのクレンジングは統計学の基本的な処理です。競馬予想においては、競走中止、失格、降着などが発生したイレギュラーなレースを学習データから取り除くことが重要です。これによって、機械学習モデルの品質が高くなります。
説明変数をチューニング
ポイントは次の3つです。
- 学習データを作る際、いきなりすべての説明変数を使わず、SQLを使って回収率や的中率を検証しながら、段階的に追加していくことが重要です。このプロセスは「PC-KEIBA Database」が得意とする仕事です。
- レース結果に影響を与えない説明変数は不要です。また、オッズなど影響が強すぎて最終的に人気と同じような予測になる説明変数も避けるべきです。
- 新聞と赤ペンだけで予想するオッサンが考えもしないような説明変数を考えてください。例えば、競走馬の成績をそのまま使うのではなく、相対的な順位や偏差値に変換するなど、独自のアイデアが重要です。
このように説明変数を慎重に選択し、独自のアプローチを取ることで、予想の精度を向上させることができます。
LightGBMのハイパーパラメータをチューニング
LightGBMのハイパーパラメータは、モデルの性能や学習速度を改善するための設定項目です。これらのハイパーパラメータを適切に調整することで、モデルの性能を最適化し、予測の精度や学習の効率を向上させることができます。
さて、本題に入りましょう。競馬予想にも使えるLightGBMの代表的なハイパーパラメータを抜粋しました。このサイトではSQLを使って学習データを作ることを前提としてるので、SQLで同じことができるハイパーパラメータについては触れません。また、コンテストで速さを競うつもりもないので、そういうハイパーパラメータも無視してます。
管理人@PC-KEIBAが選んだハイパーパラメータは以下の8つです。これらだけでも非常に効果的にチューニングできる可能性が高いと考えています。
- lambda_l1
- lambda_l2
- num_leaves
- feature_fraction
- bagging_fraction
- bagging_freq
- min_child_samples
- num_iterations
lambda_l1
型 float
初期値 0.0 (正則化しない)
L1正則化は、モデルの過学習を防ぐために、重みの絶対値に追加のペナルティを与えます。
ペナルティの強度を増やすと、つまりこの値を大きくすると重みが小さくなります。これにより、モデルがシンプルで過学習が抑制されます。適切なペナルティの設定によって、モデルの汎用性が高まります。
lambda_l2
型 float
初期値 0.0 (正則化しない)
L2正則化は、モデルの過学習を防ぐために、重みの二乗和に追加のペナルティを与えます。
ペナルティの強度を増やすと、つまりこの値を大きくすると重みが小さくなります。これにより、モデルがシンプルで過学習が抑制されます。適切なペナルティの設定によって、モデルの汎用性が高まります。
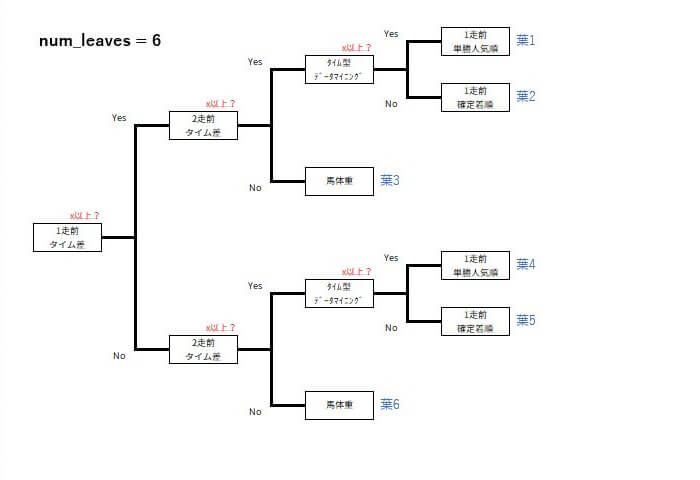
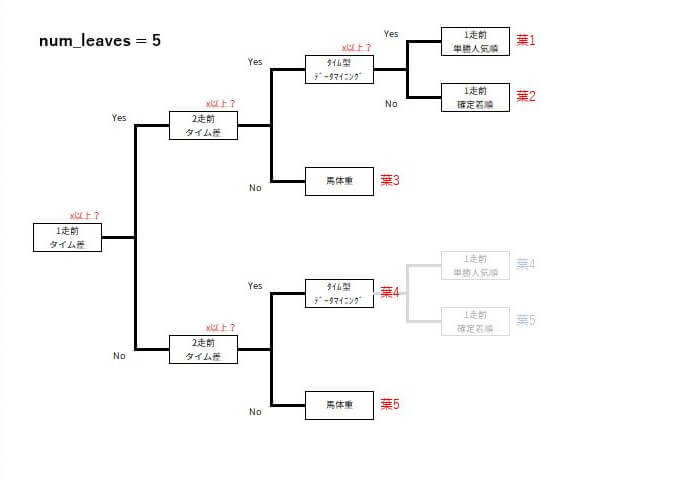
num_leaves
型 int
初期値 31
1つの決定木に含まれる葉の最大数を指定します。この値が大きいほど、モデルの複雑さが増し、より多くの特徴量の組み合わせを学習できますが、過学習のリスクも高まります。
例えば、num_leavesを6から5に減らすと、決定木の形状がこんな感じに変化します。
feature_fraction
型 float
初期値 1.0
個々の決定木の学習に使う特徴量の割合を指定します。0から1の間の値を設定し、その割合だけランダムに特徴量が選択されます。これにより、過学習が抑制され、モデルの汎用性が高まります。
bagging_fraction
型 float
初期値 1.0
データの一部をランダムに選んで取り出す際の割合を指定します。0.0から1.0の間の値を設定し、その割合だけデータをランダムに選択して学習に使います。これにより、モデルの多様性を増やし、過学習を抑制する効果があります。
bagging_freq
型 int
初期値 0 (バギングしない)
バギング(bagging)を適用する頻度を指定します。設定した値でバギングが行われます。例えば、1を設定すると、個々の決定木の学習でバギングが適用されます。これにより、過学習を抑制する効果があります。
「バギング」は、データの一部をランダムに選んで取り出し、複数の決定木に学習させて、それらの結果を組み合わせる手法です。
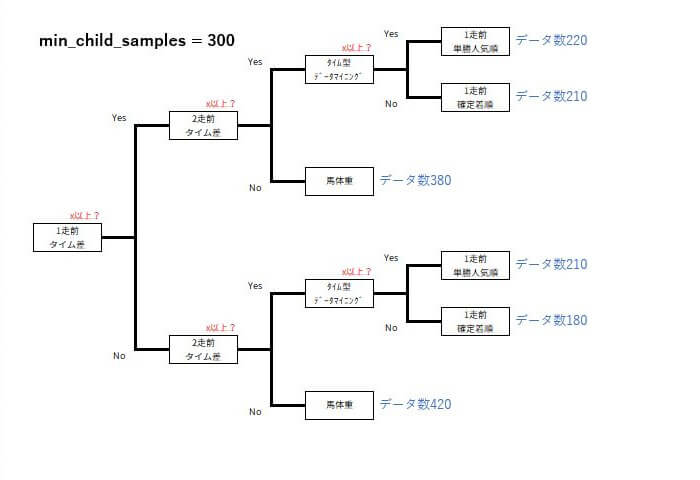
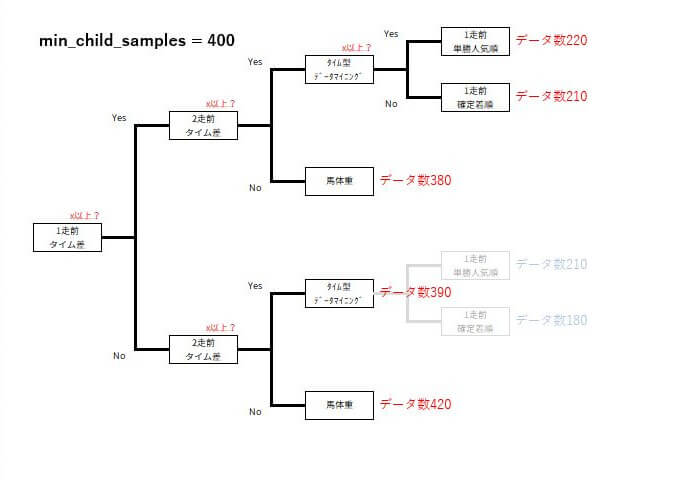
min_child_samples
型 int
初期値 20
葉の最小サンプル数を指定します。葉が分割される際に必要な最小サンプル数を設定します。この値が大きいほど、過学習を抑制する効果があります。
例えば、min_child_samplesを300から400に増やすと、決定木の葉がより多くのデータを含むようになり、モデルの安定性が向上する可能性があります。
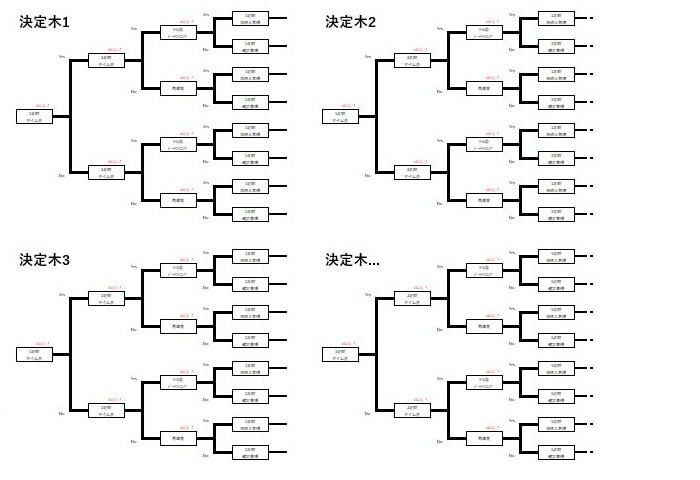
num_iterations
型 int
初期値 100
num_iterationsは、試行する決定木の本数を指します。この値を増やすと、予測精度の高いモデルを得る可能性が高くなりますが、その代わりに計算に時間がかかることがあります。
ハイパーパラメータを書く場所
この記事で紹介したハイパーパラメータは「学習用ソースコード」に書きます。
この「AI競馬」のカテゴリで無料で公開しているソースコードを例に説明します。
二値分類(binary)
二値分類の場合「# LightGBM ハイパーパラメータ」のコメントがある部分に追記します。こんな感じです。区切り文字のカンマ(,)を忘れないよう注意。
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error', # 評価指標 : 正答率
'lambda_l1':0.0,
'lambda_l2':0.0,
'num_leaves':31,
'feature_fraction':1.0,
'bagging_fraction':1.0,
'bagging_freq':0,
'min_child_samples':20,
'num_iterations':100
}・多クラス分類(multiclass)
・回帰分析(regression)
・ランキング学習(lambdarank)
の場合も同じです。
チューニングとは(まとめ)
- 使える学習データを作る。目的変数に影響を与えている説明変数を追求する。
- 過学習を防ぐためにシンプルな決定木を作る。
- 予測精度を上げるために複雑な決定木を作る。
これらをええ塩梅に調整するのが腕の見せ所。
チューニングは、この記事だけじゃなくてLightGBMの技術に特化したサイトなども参考にすることで、より深い理解とスキルの向上が期待できます。
次の記事では、Optunaを用いたハイパーパラメータの自動調整について詳しく解説しています。
■Optunaで競馬予想AIモデルをチューニング
https://pc-keiba.com/wp/optuna/
以上、「PC-KEIBA Database」が皆様のお役に立てれば幸いでございます。

