
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■競馬予想AIの作り方
https://youtu.be/rVpYF4re2iY
はじめに
この記事では「PC-KEIBA Database」のユーザー様を対象に、LightGBMを使った競馬予想AIの作り方を解説します。理解しやすくするため、ここでは最低限必要な環境の準備と、機械学習の基本に焦点を当てます。
そのため、LightGBMや機械学習についての教科書的な話を求めてる人には、あまり向いてないかもです。専門用語の使用は最小限にしますが、理解できない用語が出てきた場合はググってください。
「LightGBM」を知らない人は、この記事を読む前にググってみることをオススメします。それにより、記事の内容をより楽しく理解できるかもしれません。
競馬予想AIの作り方
当サイトの「AI競馬」の記事と「PC-KEIBA Database」があれば、競馬予想AIは簡単に作れます。必要なのは、CSV形式の学習データを用意することだけです。
記事の内容はすべて「サンプル」であることに留意してください。最終的には、それらを自分のニーズに合わせてカスタマイズし、最強の競馬予想AIを完成させてください。
Pythonのソースコードを編集するには
Pythonのソースコードを編集するには、無料のテキストエディタ「サクラエディタ」が便利です。複雑で使いもしない機能が満載の開発環境は必要ありません。サクラエディタについては、以下のマニュアルを参考にしてください。
■サクラエディタのインストールと初期設定
https://pc-keiba.com/wp/sakura-editor-setting/
記事にあるPythonのソースコードは、ほぼそのまま使えます。LightGBMパラメータを調整する場合のみ、カスタマイズが必要です。
Pythonのインストール
まず、バージョン3.x.xの「Python」をインストールします。「Python」は、データ分析や人工知能のシステム開発に非常に人気の高いプログラミング言語です。
インストール方法は、次のGoogleの検索結果からお使いのWindows 10、11に合った方法を参考にしてください。→Python インストール
開発環境を構築する必要はありません。ここでは、バージョン3.x.xの「Python」のインストールだけでOKです。
Googleの検索結果、つまり、最新の情報および分かりやすいサイトは時間と共に変化します。なので、ここにはあえて書きません。
ライブラリのインストール
次にLightGBMを使うために必要な、4つのライブラリをインストールします。
「ライブラリ」とは、プログラミングで使う汎用的なコードや機能のまとまりです。
- pandas
- scikit-learn
- LightGBM
- Matplotlib
これらは定番かつPythonの機械学習には必須のライブラリです。特に勉強する必要もありませんが、それぞれの役割とか詳細はググってください。
「Matplotlib」はどうしても必須じゃないですが、便利なライブラリなので入れときましょう。当サイトで公開しているPythonのソースコードでも使ってます。
pandas のインストール
それでは「pandas」を例に、具体的なインストール方法を説明します。「pandas」とは、Pythonのライブラリであり、データ分析システムの開発をサポートする汎用のモジュール群です。バージョンについては、後述するpipコマンドが適切なバージョンを自動的に選択してくれるため、特に気にする必要はありません。
まず、PCモニターの下にあるWindowsの検索ボックスに「cmd」と入力します。※検索ボックスが無い場合は虫眼鏡のアイコンをクリック。

出てきた「コマンドプロンプト」をクリックして起動します。
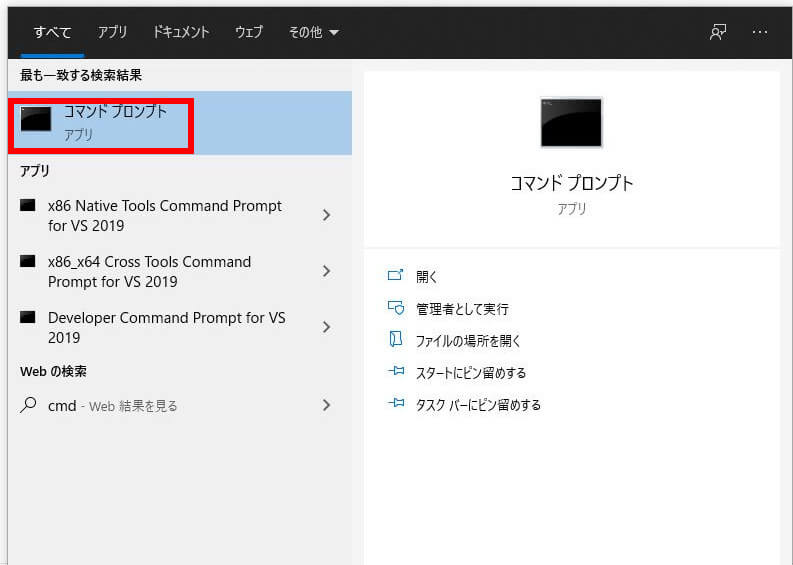
そして次のコマンドを、コマンドプロンプトに入力します。
py -m pip install pandas上記の文字(コマンド)をドラッグして、キーボードの「Ctrl」キーと「C」キーを同時に押せばコピーできます。コマンドプロンプトへの入力(貼り付け)は「Ctrl」キーと「V」キー。何のこっちゃ分からなければ直接手入力でもOK。
次の画像のような状態にできたらキーボードの「Enter」キーを押します。インストールが始まります。
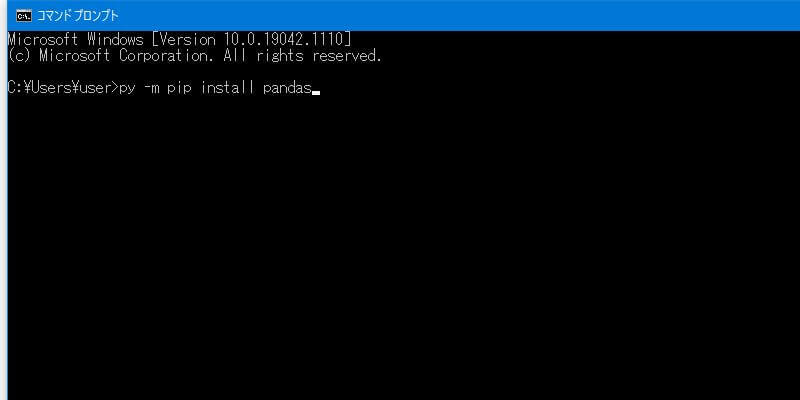
しばらく待って、コマンドプロンプトを起ち上げたときの最初の文字(※この例では “C:\Users\user>”)が出てきたらインストール完了です。
その他のライブラリのインストール
インストールの手順は先ほどの「pandas」と同じです。コマンドが違う以外は全く同じです。コマンドプロンプトもそのまま使えばOKです。次のコマンドを、コマンドプロンプトで実行してください。
py -m pip install scikit-learnpy -m pip install lightgbmpy -m pip install matplotlib場合によって少し時間がかかります。それぞれ、コマンドプロンプトの画面がコマンドを入力する直前と同じ状態になったら完了です。
たったこれだけでLightGBMによるAI競馬予想の環境が整いました。
Pythonの最新化
おまけでPythonを最新化するコマンドも書いときます。
python.exe -m pip install --upgrade pip機械学習の知識
「機械学習」とは、人工知能を実現するための技術の1つです。この技術は、大量のデータから正解に対するパターンを自動的に学習します。そして、その学習した内容を基に、未知のデータに対して予測や分類を行います。個人的には、統計学の重回帰分析と同じプロセスだと捉えてます。
この記事のテーマは、機械学習を使って競馬予想AIを作ることです。これから機械学習の話を進めていく上で、最低限知っておく必要がある用語を今から3つ説明します。
- 目的変数
- 説明変数
- 学習データ
目的変数
「目的変数」とは、予測したい項目および数値です。目的変数は1つだけ決めます。競馬予想の場合、考えられる目的変数は、着順、走破タイム、単勝人気順などです。
ちなみに、LightGBMは良い評価であるほど目的変数の数値が大きい想定で設計されてます。例えば、着順を目的変数とする場合、
- 1着は最大の数値に、
- 最下位は最小の数値にしてくれ、
ということです。
説明変数
「説明変数」とは、目的変数に対して影響があるんじゃないか?と考えられる項目および数値です。競馬予想の場合、考えられる説明変数は、前走の着順、タイム差、勝率などです。
競馬予想には、説明変数を複数用意する必要があります。だって、「タイム」や「血統」みたいな1つの要素だけでレースの結果が決まるなんて、ありえないですよね?
数値以外の項目を説明変数にするには、ダミー変数を使います。例えば、競走馬の性別を説明変数にしたい場合は、牡・セン馬を1、牝馬を2として分類するか、性別で説明変数を分けて、それぞれに1か0のフラグを立てればよいでしょう。要するに、値で分類するか、説明変数で分類するか、ということです。
学習データ
説明変数と目的変数のセットが「学習データ」です。競馬予想における学習データとは、過去のレース結果になります。このパターンを分析して未知のデータを予測するのが「機械学習」です。学習データの品質によって予測の精度が決まると言っても過言じゃありません。
競馬予想AIを作る手順
では、LightGBMを使って競馬予想AIを作るための、大まかな作業手順を説明します。
- データの分析方法を決める
- 学習データを作る
- 機械学習モデルを作る
- モデルを評価する
- 予測(予想)させる
これらの手順を順番に解説します。
データの分析方法を決める
機械学習には色んなやり方がありますが、ここでは競馬予想に応用可能な4つの分析方法を紹介します。各分析方法の詳細は、別々のページに書いてあるので、次のリンクで移動してください。
Pythonのソースコードは、それぞれのページで無料で公開してます。
学習データを作る
学習データは、SQLのSELECT文を使えば簡単に作れます。具体的なSQLは、先ほどの各分析方法の詳細で公開してます。また、PC-KEIBA Databaseの「学習データCSV出力」画面を使えば、SQLの実行結果を簡単に学習データに変換できます。
ここでは、学習データのサンプルとして、説明変数を次の内容で作ります。過去走は2走前まで使いました。目的変数はデータの分析方法に応じて、確定着順の値を加工します。
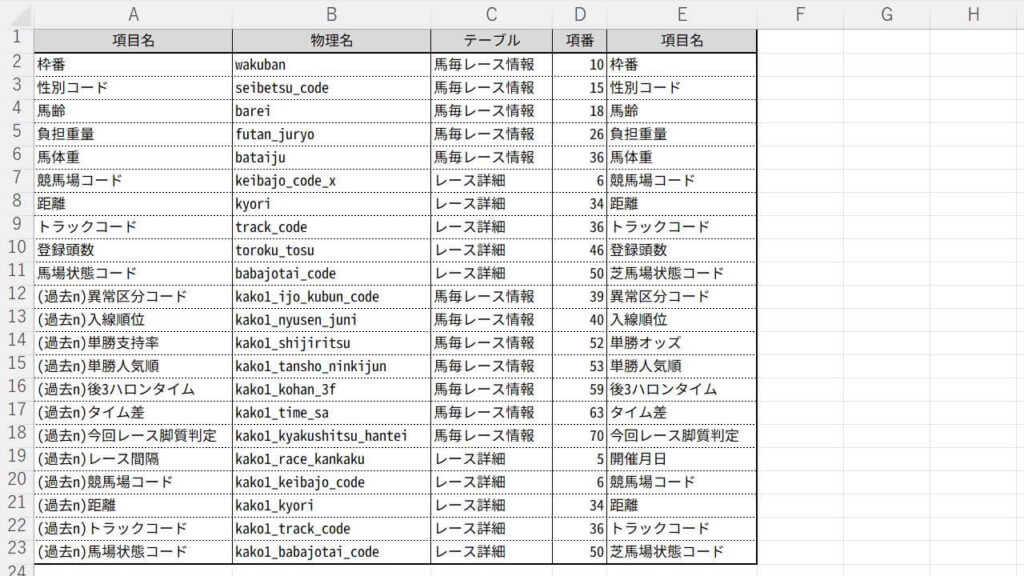
今回のサンプルでは、学習データの集計期間を、JRAの2013年~2022年までの10年間とします。各分析方法の詳細で紹介する予測には「2023/02/04(土)小倉12R」を使います。
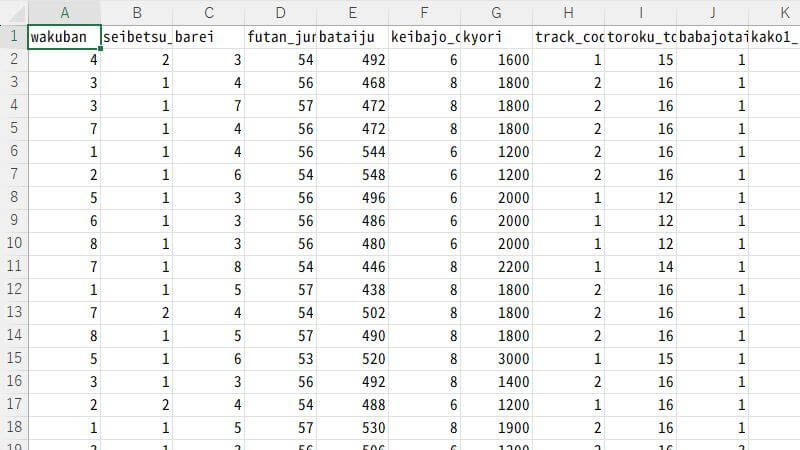
「二値分類」用の学習データを表計算ソフトで開くとこんな感じです。
機械学習モデルを作る
学習用ソースコードで、CSVファイルの学習データをLightGBMに学習させます。この学習によって得られた結果が、機械学習の世界で「モデル」と呼ばれるものです。
モデルを評価する
モデルの評価方法として、学習結果をグラフ化したり、シミュレーションしたりすることが一般的です。評価の基準は分析方法によって異なります。良いモデル、つまり現実に近い予測ができるようになるまで、回収率や的中率が高いモデルが出来るまで、評価を繰り返すことが重要です。具体的には、学習データを変えてみたり、LightGBMのパラメータをチューニングする、などの手法があります。
シミュレーションについては「シミュレーション編」の記事で、チューニングについては「チューニング編」の記事で解説しているので参考にして下さい。
予測(予想)させる
モデルの品質に納得したら、予測用ソースコードに明日のレースを予想させます。そして、馬券を買ってください。
最後に
当たり前ですが、機械学習とLightGBMに関する話は、この記事に書いてることが全てじゃありません。優れた機械学習モデルを作るための評価基準や、LightGBMの技術に焦点を当てたWebサイト、または統計学の専門書なども参考にして知識を深めてください。そもそも、それを自分で追及するのが楽しいと思うんで。
では「PC-KEIBA Database」を活用して、AI競馬予想を思う存分楽しんでください!

