
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■【競馬予想AIを学ぶ】LightGBMによるAI競馬予想(回帰分析)
https://youtu.be/d-h6Sem_JZo
この記事を読む前に「LightGBMによるAI競馬予想(準備編)」の記事を先に読んでください。その中には、機械学習の基礎知識や、学習データで使う説明変数の内容など、他のデータ分析方法と共通する説明が含まれています。
回帰分析(regression)
「回帰分析」は数値を目的変数とする場合に使う方法です。競馬予想の場合、例えば走破タイムなど。
ここに公開するPythonのソースコードは「予測誤差」と「決定係数」の評価指標と「散布図」の作成を実装しています。学習データを作るSQLで目的変数の項目名を「target」にすれば、オリジナルの学習データで分析する場合でもそのまま使えます。
ソースコードは学習用と予測用に分けてます。
欠損値(null)は、SQLで何らかの値(0など)に変換しておくことを前提にしてます。欠損値についてPythonでは何もしてないってことです。
学習用ソースコード
以下が「回帰分析」で学習するPythonのソースコードです。この学習用ソースコードのファイル名は「regression_train.py」とします。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
ソースコードはQiitaの記事から簡単にコピーできます。
※ソースコードの右上に出るアイコンをクリックしてください。
https://qiita.com/PC-KEIBA/items/8b0a4e77f856e6691e89
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
# CSVファイル読み込み
in_file_name = 'regression_train.csv'
df = pd.read_csv(in_file_name, encoding='SHIFT_JIS')
# 説明変数(x)と目的変数(y)を設定
target = 'target'
x = df.drop(target, axis=1).values # y以外の特徴量
y = df[target].values
# 訓練データとテストデータを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# LightGBM ハイパーパラメータ
params = {
'objective':'regression', # 目的 : 回帰分析
'metric':{'rmse'} # 評価指標 : 二乗平均平方根誤差
}
# モデルの学習
train_set = lgb.Dataset(x_train, y_train)
valid_sets = lgb.Dataset(x_test, y_test, reference=train_set)
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets)
# モデルをファイルに保存
model.save_model('regression_model.txt')
# テストデータの予測
y_pred = model.predict(x_test)
# 評価指標
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print('予測誤差 = ', rmse)
print('決定係数 = ', r2)
# 散布図
plt.plot(y_test, y_test, color = 'red', label = 'x=y')
plt.scatter(y_test, y_pred)
plt.title('true vs predict')
plt.xlabel('true')
plt.ylabel('predict')
plt.savefig('regression_train.png', bbox_inches='tight', dpi=500)
plt.show()このソースコードは、netkeibaが主催する予想大会の「俺プロ」で、最強位に昇り詰めた管理人@PC-KEIBAが実際に使用しているものです。その中で「最強位」とは、参加者の上位約10%のみが取得できる名誉ある称号で、競馬予想の実力を証明しています。
学習データを作る
説明変数は他の分析方法と共通にしました。内容は「LightGBMによるAI競馬予想(準備編)」の記事を見てください。学習データのファイル名は「regression_train.csv」とします。
今回のサンプルでは目的変数の「確定着順」を、次のように分類してみます。
- 1着→3
- 2〜3着→2
- 4〜5着→1
- 上記以外→0
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
LightGBMに学習させる
今回の例では、Cドライブの直下に「pckeiba」というフォルダを作って、
- 学習データ(regression_train.csv)
- 学習用ソースコード(regression_train.py)
2つのファイルを置きます。こういう状態です。
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。
cd C:\pckeibapython regression_train.pyLightGBMが学習を開始します。処理が終わると評価指標を表示します。
モデルを評価する
今回のサンプルでは評価指標として「予測誤差」と「決定係数」を表示します。
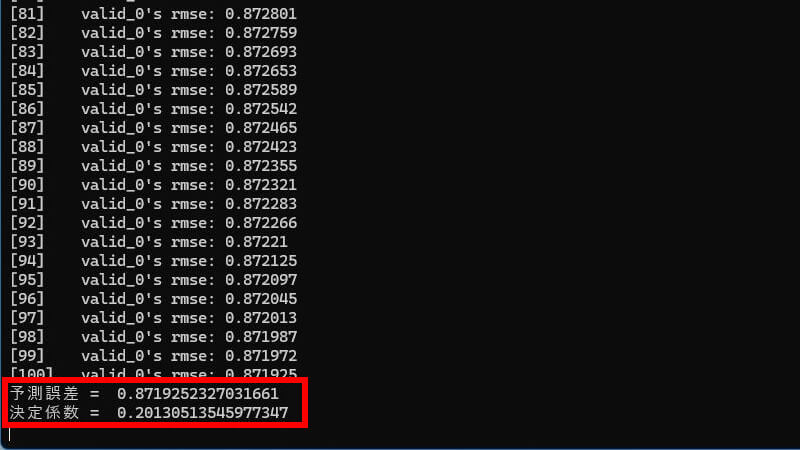
今回のモデルでは上記のような結果になりました。
- 予測誤差 = 値が小さいほどモデルの精度が良い
- 決定係数 = 1 に近いほどモデルの精度が良い
なので、とても使い物にならなさそうですね。この目的変数を走破タイムに変えるなどしたら、精度の高いモデルが出来るかもしれません。回帰分析の評価指標は、この他にもあるのでググって研究してください。
このモデルを「regression_model.txt」に保存しています。このファイルは予想するとき使います。
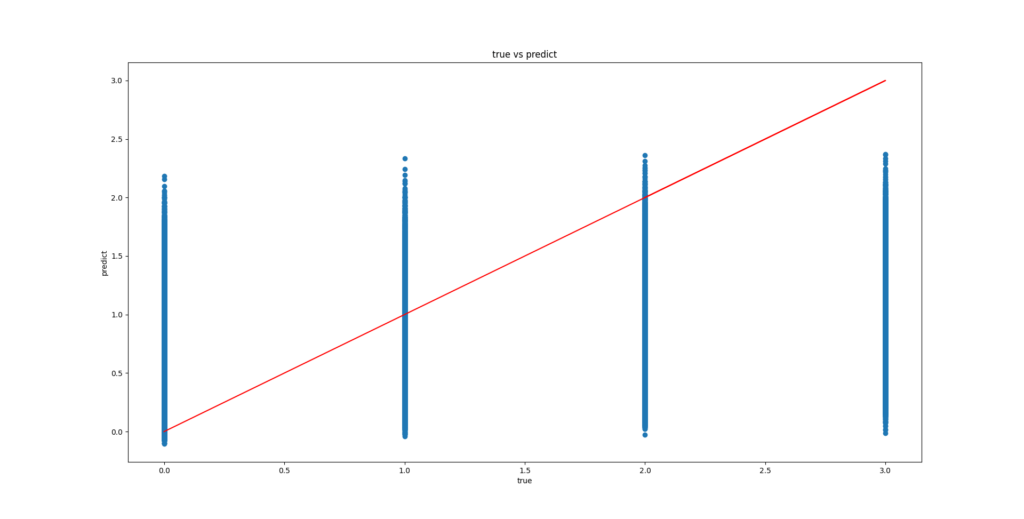
散布図
参考として「散布図」の作成を実装してます。精度が高いモデルの散布図は、赤い直線付近に青い点が密集します。でも今回のモデルは青い点が全面に散布してて散々な結果というか最悪の結果になりました。そもそも全馬の着順を予測したろうとか条件が厳しすぎるんで(笑)
これを見ながら説明変数を取捨選択したり、LightGBMパラメータをチューニングしたりします。
同じ学習データを使っても分析方法によって結果がまったく異なるという見本でもあります。
いろいろ試してモデルの精度に納得したら、これを使って明日のレースを予想させます。
予測用ソースコード
以下が「回帰分析」で予想するPythonのソースコードです。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
ソースコードはQiitaの記事から簡単にコピーできます。
※ソースコードの右上に出るアイコンをクリックしてください。
https://qiita.com/PC-KEIBA/items/8b0a4e77f856e6691e89
import pandas as pd
import numpy as np
import lightgbm as lgb
import os
import sys
# 出馬表ファイル読み込み
fname = sys.argv[1]
x_test = np.loadtxt(fname, delimiter=',', skiprows=1)
# 1行だけの場合でも2次元配列に変換
if x_test.ndim == 1:
x_test = x_test.reshape(1, -1)
# モデル読み込み
bst = lgb.Booster(model_file='regression_model.txt')
# テストデータの予測
y_pred = bst.predict(x_test, num_iteration=bst.best_iteration)
# 拡張子を除いたファイル名を取得
fname = os.path.splitext(os.path.basename(fname))[0]
# 予測値を出力
df = pd.DataFrame({'予測値':y_pred})
df.to_csv(fname + '_pred.csv', encoding='SHIFT_JIS', index=False)出馬表データを作る
予測させる出馬表データは、学習データ作成のSQLと出力後のファイルを少し改造すれば作れます。学習データとの違いは次の2つです。
- SQLで目的変数「target」の項目を消す。
- SQLで予想するレースでレコードの抽出条件を設定する。
出馬表データのファイル名は何でも良いですが、ここでは「レースID(※1).csv」とします。
今回のサンプルでは「2023/02/04(土)小倉12R」を予想してみます。
| (※1)レースID | 年月日場R yyyymmddjjrr(12桁) |
|---|
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
予測(予想)させる
先ほどと同じ「pckeiba」というフォルダに、
- 出馬表(レースID(※1).csv)
- モデル(regression_model.txt)
- 予測用ソースコード(regression_pred.py)
3つのファイルを置きます。こういう状態です。
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。2番目は、予測用ソースコードの後に、半角スペースと出馬表のファイル名です。
cd C:\pckeibapython regression_pred.py 202302041012.csv処理が終わると「予測値」のファイルが出力されます。
- レースID(※1)_pred.csv (予測値)
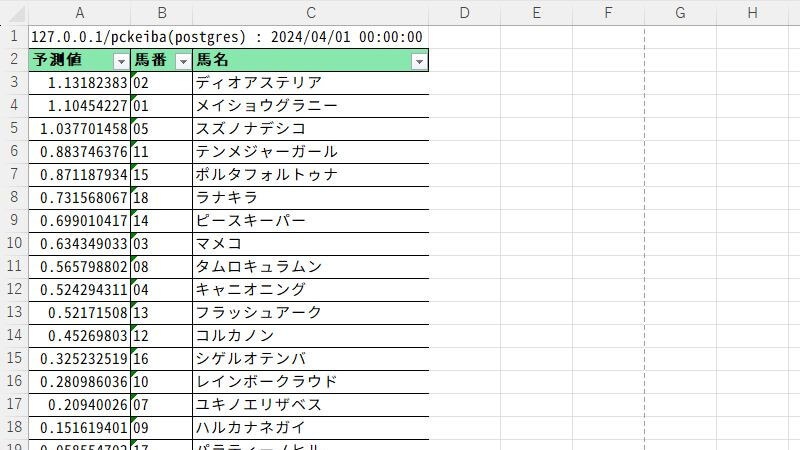
このファイルには数値データしか含まれていないので、分かりにくいかもしれませんが、出馬表データと同じ馬番の昇順で出力されます。馬券を買うときは、SQLで馬番と馬名だけの出馬表をCSVに出力して、そこへ貼り付けて予測値で並べ替えると便利です。例えば、こんな感じです。
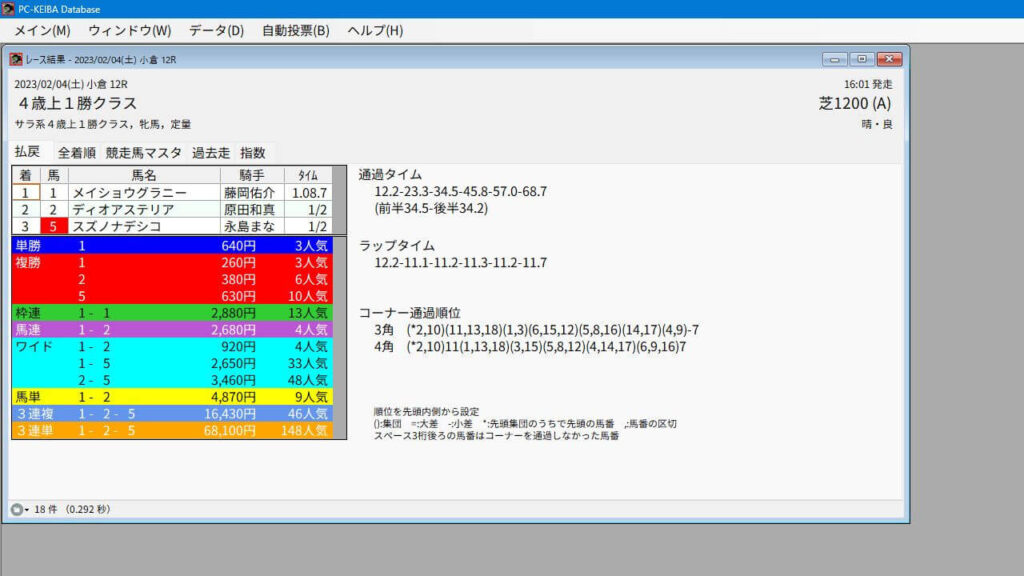
予測値の上位3頭で、レース結果は3連複の払戻金が16,430円となりました。単勝の人気順は、③⑥⑩の組み合わせでした。
「回帰分析」による競馬予想AIの話は以上です。
今回のサンプルはあくまで1つの「サンプル」でしかありません。完成させるのはユーザーのあなたです。
