
Borutaで競馬予想AIモデルをチューニング
特徴量選択は、機械学習において重要な前処理の一つです。データセットから最も重要な特徴量を選ぶことで、モデルのパフォーマンスを向上させることができます。ここでは、LightGBMでBorutaというライブラリを使用して特徴量選択を行う方法について解説します。
特徴量選択の重要性とメリット
- モデルの精度向上:不要な特徴量を削除することで、モデルの予測精度が向上することがあります。
- 計算コストの削減:特徴量が減ることで、モデルのトレーニングや予測にかかる時間が短縮されます。
- 過学習の防止:重要でない特徴量が多いと、モデルがノイズに適応しすぎて過学習のリスクが高まります。特徴量を絞ることでこのリスクを軽減できます。
- 解釈性の向上:特徴量が少ないと、モデルの結果を理解しやすくなり、競馬予想における意思決定がしやすくなります。
Borutaの概要
「Boruta(ボルタ)」は、ランダムフォレストアルゴリズムを基にした特徴量選択手法で、重要な特徴量を選定するための強力なツールです。Borutaの主な特長は以下の通りです。
- 目的:Borutaの目的は、重要な特徴量とそうでない特徴量を区別することです。
- アルゴリズムの基礎:ランダムフォレストを利用して、特徴量の重要性を評価します。
- 反復プロセス:Borutaは反復的に特徴量の重要性を評価し、重要な特徴量を選別します。
「ランダムフォレスト」は、複数の決定木を組み合わせて予測精度を高めるアンサンブル学習手法です。各決定木は異なるデータサブセットと特徴量サブセットを用いて訓練され、全体の予測結果を多数決や平均で統合します。この手法により、過学習を防ぎながら高い予測精度を実現します。分類や回帰問題に対して強力で信頼性の高いモデルです。
Borutaの動作原理
- シャドウ特徴量の生成:オリジナルの特徴量に加え、ランダムにシャッフルされたシャドウ特徴量を追加します。このシャドウ特徴量は、ランダムで生成された無意味なデータです。
- ランダムフォレストの適用:ランダムフォレストを使用して、オリジナルの特徴量とシャドウ特徴量の重要度を計算します。
- 特徴量の評価:各特徴量の重要度をシャドウ特徴量と比較します。オリジナルの特徴量がシャドウ特徴量よりも重要である場合、その特徴量は「重要」と見なされます。
- 特徴量の選別:重要度の高い特徴量は「確定」、低い特徴量は「非確定」としてマークされます。その他の特徴量は「不確定」とされ、次の反復で再評価されます。
- プロセスの反復:反復的に評価を行い、全ての特徴量が「確定」または「非確定」となるまでプロセスを繰り返します。
Borutaの利点
- 高い信頼性:シャドウ特徴量との比較により、特徴量の重要度をより信頼性高く評価できます。
- 自動化:特徴量選択のプロセスが自動化されており、手動でのチューニングが不要です。
- インタープリタビリティ:結果が明確であり、選ばれた特徴量が重要である理由を理解しやすいです。
Borutaのインストール
Borutaを使うには、コマンドプロンプトを起動し、次のコマンドを実行してください。
py -m pip install borutaコマンドプロンプトの使い方は、以下の記事を参考にしてください。
■LightGBMによるAI競馬予想(準備編)
https://pc-keiba.com/wp/lightgbm/
Borutaの使い方
Borutaを使うには、既存のソースコードに数行の修正を加えるだけでOKです。ここでは、「二値分類」の記事で使ったソースコードを例に説明します。
・多クラス分類(multiclass)
・回帰分析(regression)
の場合も同じです。適宜、読み替えてください。
学習用ソースコード (Boruta Ver.)
以下が、Borutaバージョンの「二値分類」で学習するPythonのソースコードです。この学習用ソースコードのファイル名は「binary_train_selected_features.py」とします。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、この記事の最後の、有料会員限定のダウンロードリンクからも、ファイルをダウンロードできます。
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
np.float = float
np.int = int
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from boruta import BorutaPy
from sklearn.ensemble import RandomForestClassifier
# CSVファイル読み込み
in_file_name = 'binary_train.csv'
df = pd.read_csv(in_file_name, encoding='SHIFT_JIS')
# 説明変数(x)と目的変数(y)を設定
target = 'target'
x = df.drop(target, axis=1).values # y以外の特徴量
y = df[target].values
# 訓練データとテストデータを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# Borutaによる特徴量選択
estimator = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
feature_selector = BorutaPy(estimator=estimator, n_estimators='auto', random_state=0, verbose=2, alpha=0.05, max_iter=100)
feature_selector.fit(x_train, y_train)
x_train = feature_selector.transform(x_train)
x_test = feature_selector.transform(x_test)
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error', # 評価指標 : 正答率
'num_boost_round':100
}
# モデルの学習
train_set = lgb.Dataset(x_train, y_train)
valid_sets = lgb.Dataset(x_test, y_test, reference=train_set)
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets, num_boost_round=100)
# モデルをファイルに保存
model.save_model('binary_model.txt')
# テストデータの予測
y_prob = model.predict(x_test)
y_pred = np.where(y_prob < 0.5, 0, 1)
# 評価指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print('正解率 = ', accuracy)
print('適合率 = ', precision)
print('再現率 = ', recall)
# 特徴量重要度
importance = np.array(model.feature_importance())
selected_features = feature_selector.support_ # Borutaによって選択された特徴のインデックス
feature = df.drop(target, axis=1).columns[selected_features]
df = pd.DataFrame({'feature':feature, 'importance':importance})
df = df.sort_values('importance', ascending=True)
n = len(df) # 説明変数の項目数を取得
values = df['importance'].values
plt.barh(range(n), values)
values = df['feature'].values
plt.yticks(np.arange(n), values) # x, y軸の設定
plt.savefig('binary_train.png', bbox_inches='tight', dpi=500)
plt.show()修正したソースコード
■修正前
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error' # 評価指標 : 正答率
}# モデルの学習
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets)■修正後
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error', # 評価指標 : 正答率
'num_boost_round':100
}# モデルの学習
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets, num_boost_round=100)追加したソースコード
from boruta import BorutaPy
from sklearn.ensemble import RandomForestClassifier# Borutaによる特徴量選択
estimator = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
feature_selector = BorutaPy(estimator=estimator, n_estimators='auto', random_state=0, verbose=2, alpha=0.05, max_iter=100)
feature_selector.fit(x_train, y_train)
x_train = feature_selector.transform(x_train)
x_test = feature_selector.transform(x_test)# 特徴量重要度
selected_features = feature_selector.support_ # Borutaによって選択された特徴のインデックス
feature = df.drop(target, axis=1).columns[selected_features]削除したソースコード
# 説明変数の項目名を取得
feature = list(df.drop(target, axis=1).columns)Borutaの実行
では、「二値分類」の記事で使った同じ学習データを用いて、Borutaで特徴量選択を行い、その結果を比較してみましょう。
今回の例では、Cドライブの直下に「pckeiba」というフォルダを作って、
- 学習データ(binary_train.csv)
- 学習用ソースコード(binary_train_selected_features.py)
2つのファイルを置きます。こういう状態です。
学習データの作り方は、以下の記事を参考にしてください。
■LightGBMによるAI競馬予想(二値分類)
https://pc-keiba.com/wp/binary/
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。
cd C:\pckeibapython binary_train_selected_features.pyLightGBMが学習を開始します。処理が終わると評価指標を表示します。
実行時間は約4分かかりました。このモデルを「binary_model.txt」に保存しています。このファイルは予想するとき使います。
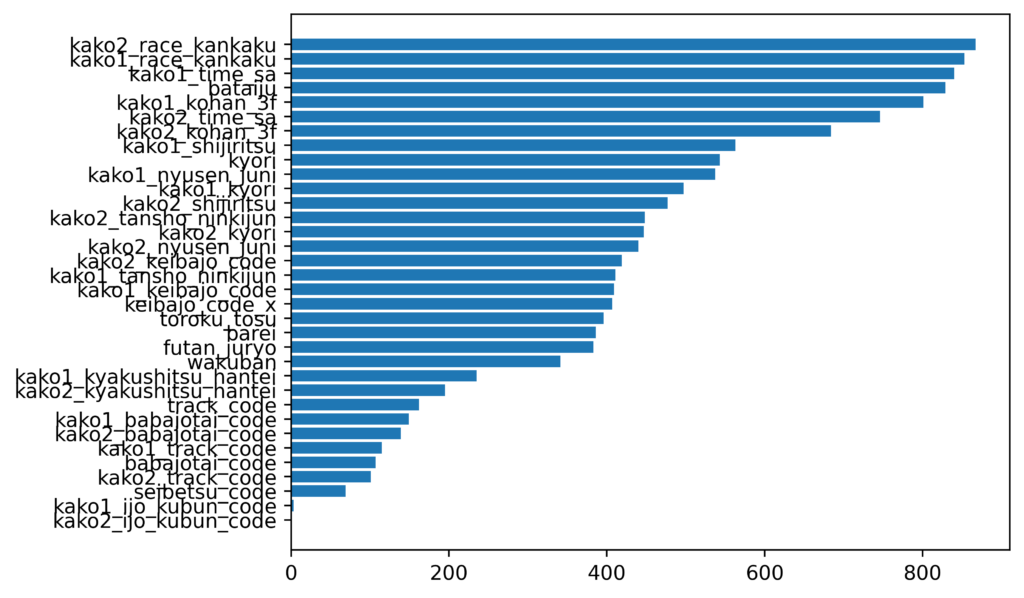
特徴量重要度の比較
チューニング前
チューニング後
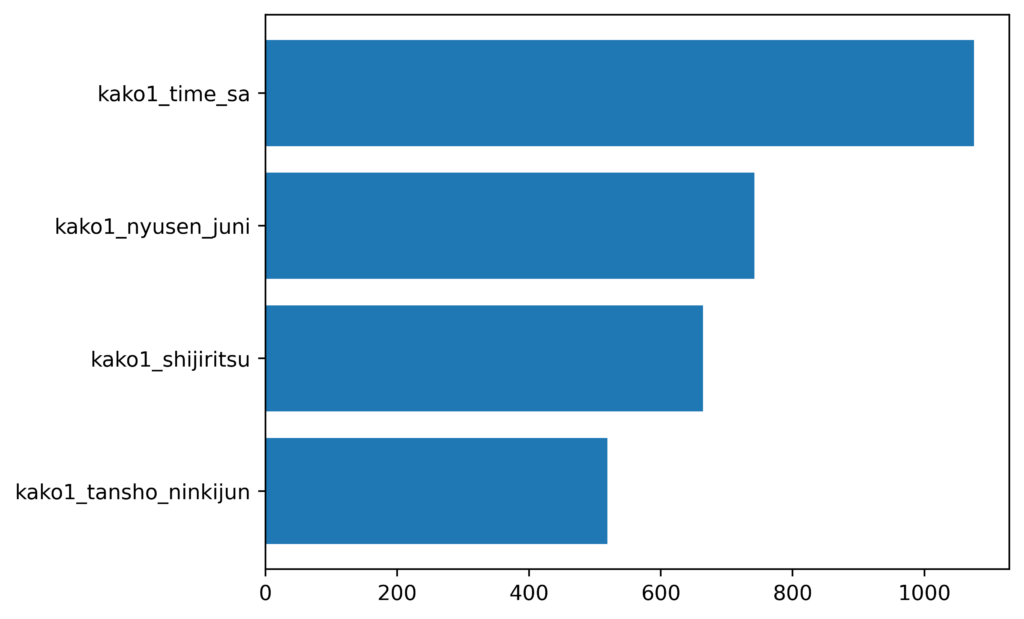
特徴量が34から4に大幅に減少しました。
評価指標の比較
チューニング前
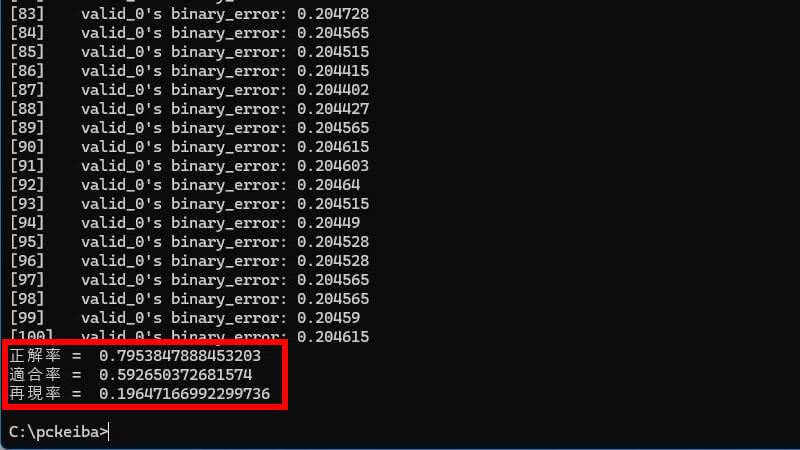
チューニング後
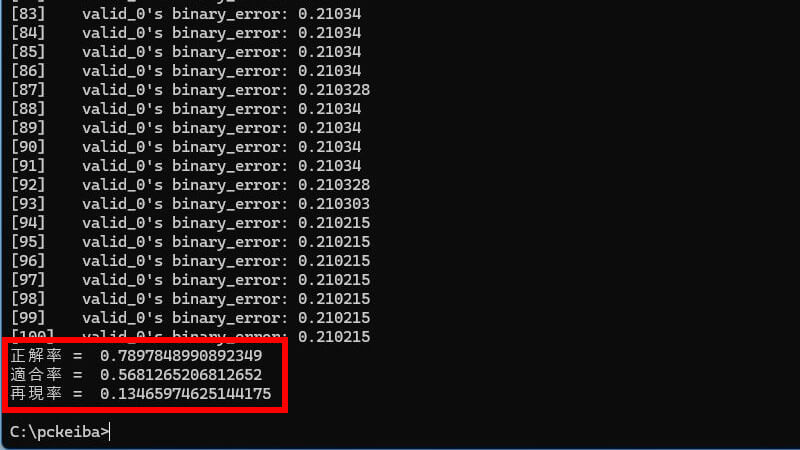
評価指標はすべて低下しました。しかし、特徴量が34から4に大幅に減少したにもかかわらず、正解率と適合率はそれほど低下しませんでした。評価指標の結果は期待通りではありませんでしたが、これはあくまで今回のモデルに限った話です。LightGBMでBorutaを使う方法として参考にしてください。
Borutaの話は以上です。「PC-KEIBA Database」で思う存分、AI競馬予想を楽しんでください!

