
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■コンピ指数でレースの波乱度を予測する
https://youtu.be/y1VHaPzL7c0
コンピ指数でレースの波乱度を予測する
今回はレースの波乱度を予測する機械学習モデルを開発してみます。具体的には、LightGBMを用いて、コンピ指数1位馬が3着以内に入るかどうかを予測します。出馬表確定時点で予測を行うことで、競馬予想に役立てることを目的としています。
コンピ指数は、日刊スポーツが独自に算出した馬の能力指数です。指数は40から90までの数値で表され、指数が大きいほど能力が高いと判断されます。コンピ指数の価値とは競馬予想の成績やらではなく、出馬表確定の時点でレース確定後の単勝人気の傾向とだいたいあってる、ってとこにある、と個人的に思ってます。
次のデータを見ると、コンピ指数1位馬が3着以内に入るかどうかは、払戻金に大きな影響を与えていることが分かります。
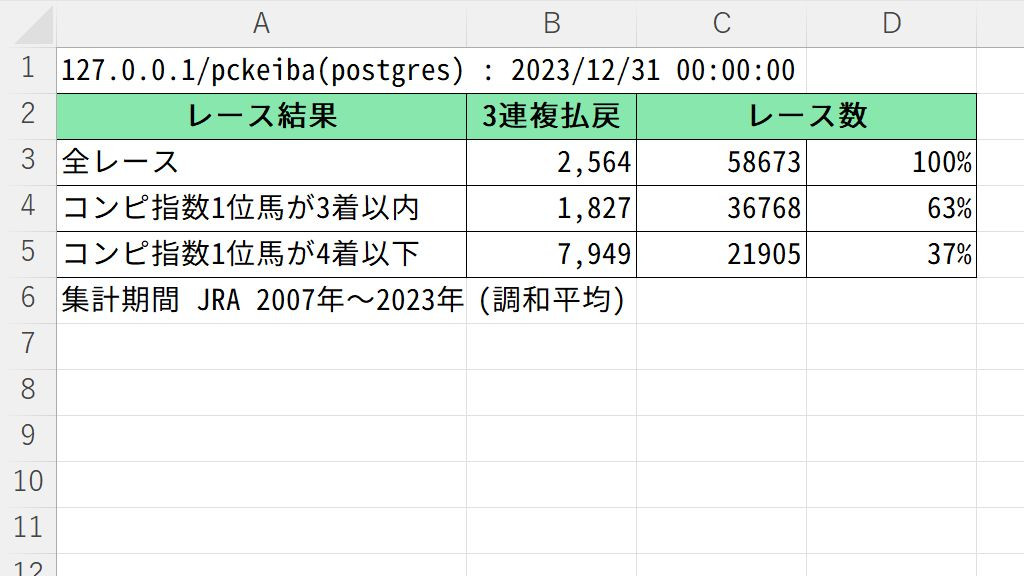
競馬予想において、1番人気の選択は重要なテーマです。これは競馬予想に有効な予測となる可能性があります。コンピ指数1位馬が4着以下になる確率が高いレースに絞って穴狙いにするとか、色んな使い方が考えられます。
学習データを作る
目的変数
まず、目的変数を決めます。データの分析方法は「二値分類」を採用し、目的変数は以下のように定義しました
- 1 = コンピ指数1位馬が3着以内
- 0 = コンピ指数1位馬が4着以下
ちなみに、LightGBMは良い評価であるほど目的変数の数値が大きい想定で設計されてます。
説明変数
次に、説明変数を決めます。コンピ指数1位馬が3着以内に入るか否かに影響を与えそうな、以下の項目を説明変数の候補にしました。
説明変数として使えるのは数値データのみです。
- コンピ指数
- 競馬場コード&トラックコード
- 出走頭数
馬場状態コードも影響を与えると考えられますが、発走直前にしか分からないので無視します。競走条件コード、距離も影響を与える可能性が考えられますが、そこまで具体化するとデータ件数が少なくなるので無視します。
データの前処理
LightGBMはデータそのものや利用目的を理解できないため、事前に人間によるデータの前処理が必要です。
コンピ指数1位馬の複勝率を条件別に集計してみる
今回の目的は、コンピ指数1位馬がレースで3着以内に入るかを予測することです。そのために、データの前処理として、競馬場コード&トラックコードの組み合わせでコンピ指数1位馬の複勝率を集計し、説明変数にしてみます。
あとで学習データを作るとき使うため、集計結果をテーブルに保存しておきます。PostgreSQLでSELECT文の実行結果をテーブルに保存するには、SELECT文の直前に「CREATE TABLE~」を追加すればOKです。
CREATE TABLE table_name AS
SELECT~このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
そうすると、こんな感じのテーブルが出来上がります。
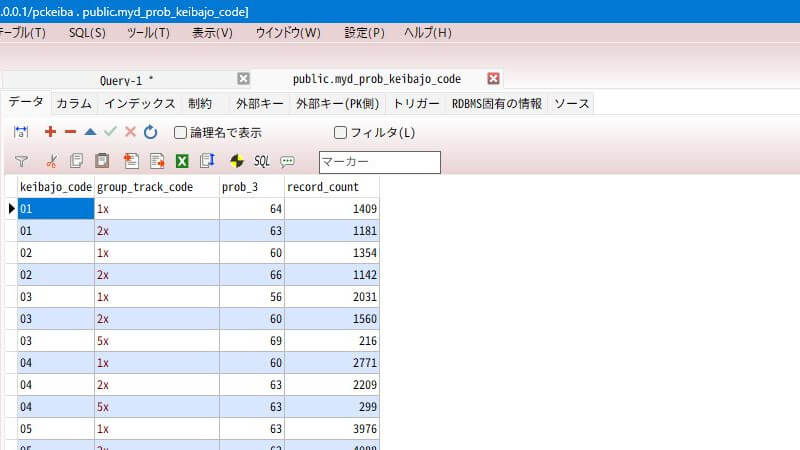
データを見ると、最高は小倉の障害で71%、最低は福島の芝で56%という結果が得られ、各競馬場のトラックの違いによって15%の差があることが分かりました。
コンピ指数の影響度を先に検証する
出走頭数も、コンピ指数1位馬の複勝率に大きく影響する可能性があると思いました。しかし、データの粒度を統一し、コンピ指数の順位がどこまで影響度が高いかを先に検証するために、まずは出走頭数が16頭のレースに絞って学習データを作ってみます。16頭のレースを選んだ理由は、全体の34%と最も多く、データ分析に適しているからです。
余談ですが、少頭数のレースでは展開の紛れが少ないため、1番人気の勝率が高いという意見があります。しかし、これは確率分母の小ささによる勝率の見かけ上の上昇であり、必ずしも出走頭数と展開の紛れの関係を示すものではありません。実際のデータでは、少頭数のレースでは人気薄も勝率が高くなる傾向があり、これが出走頭数と展開の紛れが必ずしも密接でないことの証拠と言えるでしょう。
モデルの学習と評価
LightGBMに学習させる
データの前処理が終わったら、次は「LightGBMによるAI競馬予想(二値分類)」の記事を参考に、LightGBMに学習させます。学習データはコンピ指数が提供されているJRA 2007年から2022年までを使いました。
試行 1/5回目
1回目は出走頭数が16頭のレースに絞って学習させてみます。コンピ指数も16位まで説明変数に加えました。
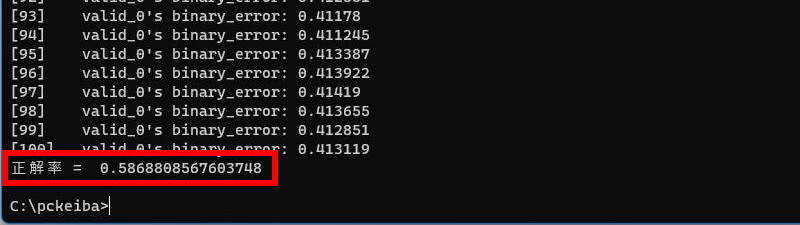
正解率 = 58.6%
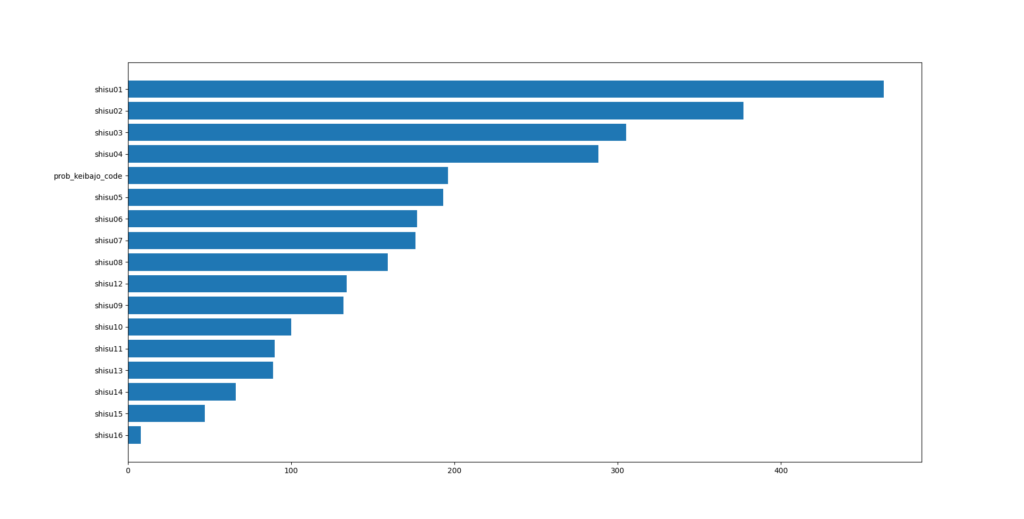
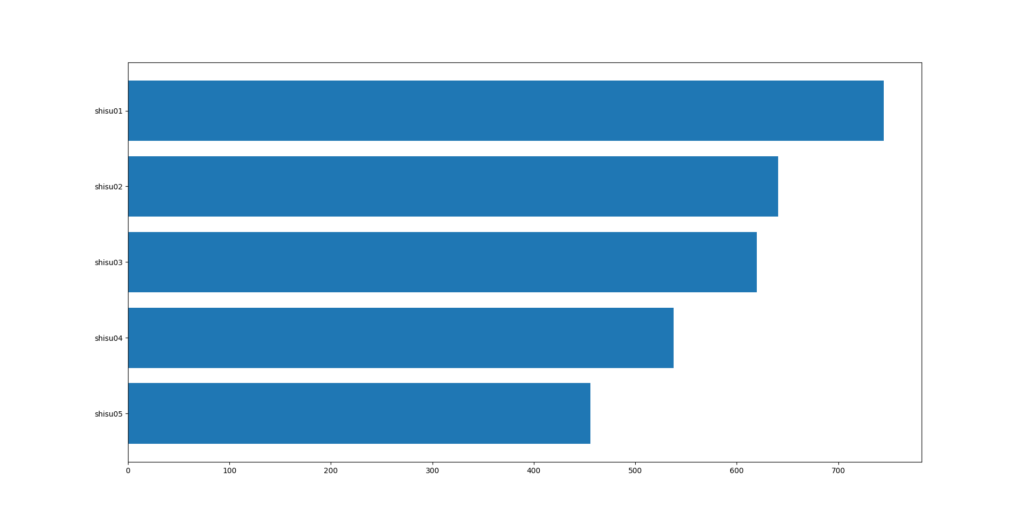
「特徴量重要度」のグラフを見ると、1位~4位のコンピ指数がブッチギリでコンピ指数1位馬の複勝率に影響してるようです。
せっかく集計した競馬場コード&トラックコードの複勝率は、期待してたほどの影響は見られませんでした。そのため、これらのデータを説明変数から除外して再度、学習させてみます。
試行 2/5回目
2回目は出走頭数が16頭のレースに絞ったまま、説明変数をコンピ指数1位~4位だけで学習させてみます。
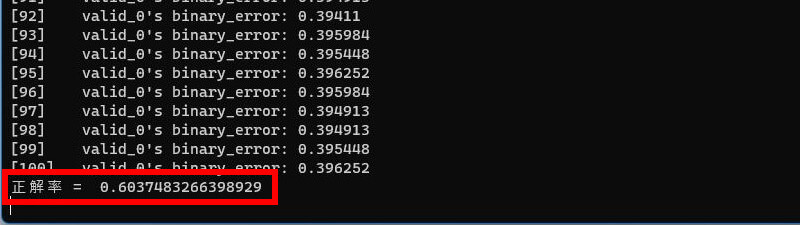
正解率 = 60.3%
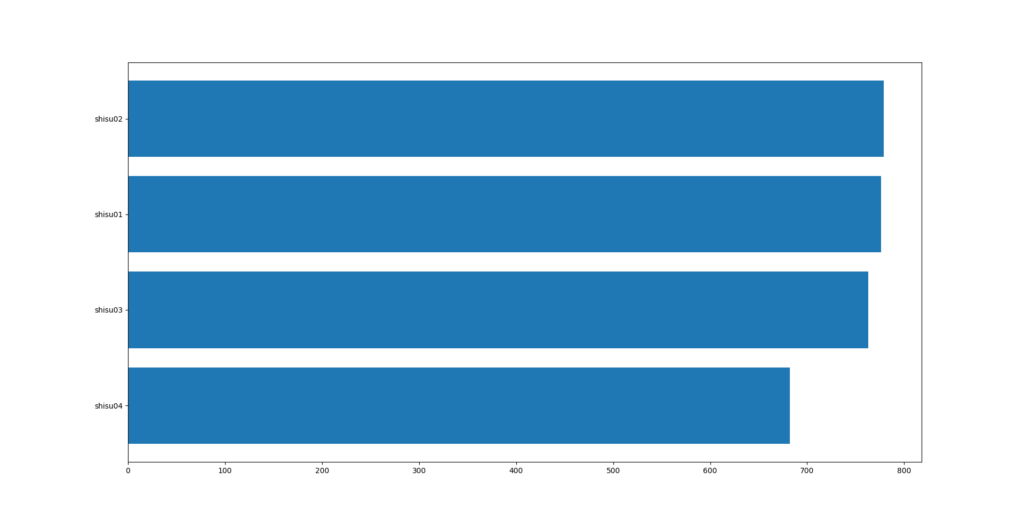
1位~4位のコンピ指数だけで学習させた結果、正解率が1.7%向上しました。他の説明変数は蛇足だった可能性が高いです。
試行 3/5回目
試しに競馬場コード&トラックコードの複勝率を説明変数に加えます。
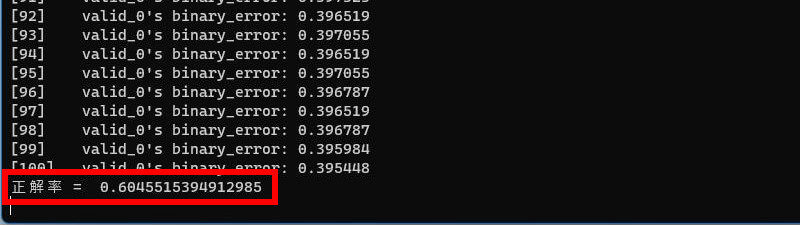
正解率 = 60.4%
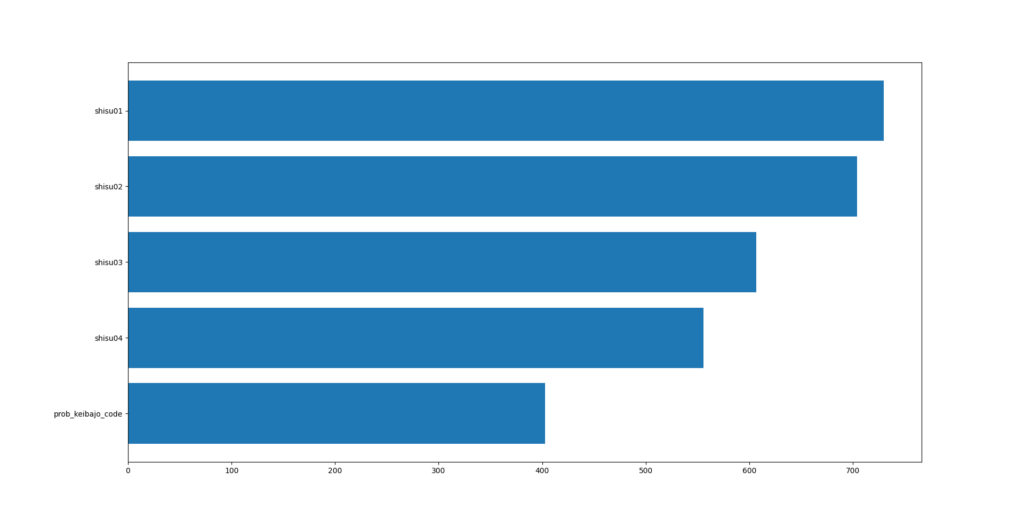
わずかですが正解率が向上しました。しかし上昇幅は、わずか0.1%なので説明変数から除外することにします。その理由は、説明変数をできるだけ抽象化して汎用性を高めたいからです。
試行 4/5回目
4回目は出走頭数が16頭のレースに絞ったまま、説明変数をコンピ指数1位~5位だけで学習させてみます。
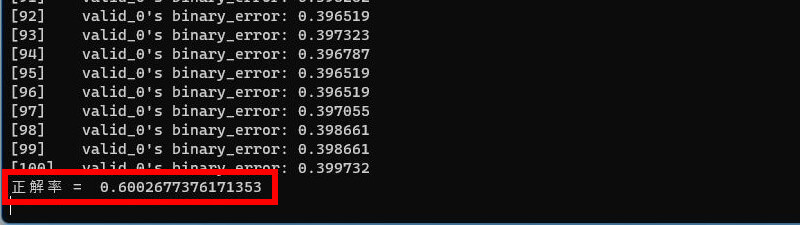
正解率 = 60.0%
コンピ指数を1位~5位で学習させた場合、正解率がわずかに低下(60.3%→60.0%)しました。出走頭数が16頭のレースのみを対象とした調査結果から、1位~4位のコンピ指数を使うことが最適であると判断しました。
試行 5/5回目
5回目は出走頭数の絞り込みをやめて、出走頭数を説明変数に加えます。
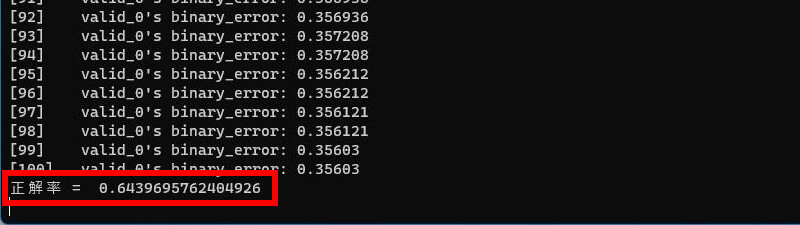
正解率 = 64.3%
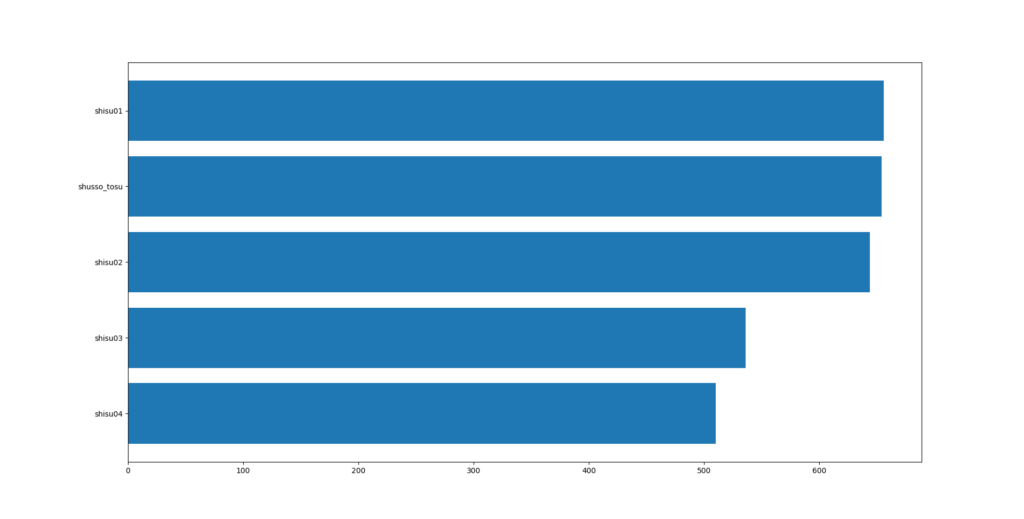
ここまでの結果から、出走頭数を説明変数に加えて学習させたら、予想通り正解率が向上しました。最初の試行と比較して正解率が5.7%向上しました。
つまり、出走頭数はコンピ指数1位馬の複勝率に影響している、ということです。今回は、ひとまずこの品質で機械学習モデルを完成とすることにしました。
管理人@PC-KEIBAはいつもこのようなやり方で遊んでますが、実際には他にもいろいろ試した上で記事としてまとめています。
Pythonデータ登録
完成した機械学習モデル(binary_model.txt)を使って、実際に予測を行ってみます。学習データは2007年から2022年までの期間を使ったので、2023年のレース(1年分)を予測してみます。
テストデータを作る
予測させるテストデータはイチから作るのではなく、先ほどの学習データに「レースID」と「馬番」を加えるだけのSQLです。これにはSELECT文の結果で新しいテーブルを作るSQLを使います。
今回のテストデータはCSVファイルじゃなくてデータベースのテーブルに保存します。
CREATE TABLE table_name AS
SELECT~このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
そうすると、こんな感じのテーブルが出来上がります。説明変数の前に、主キーの「レースID」と「馬番」を加えてます。
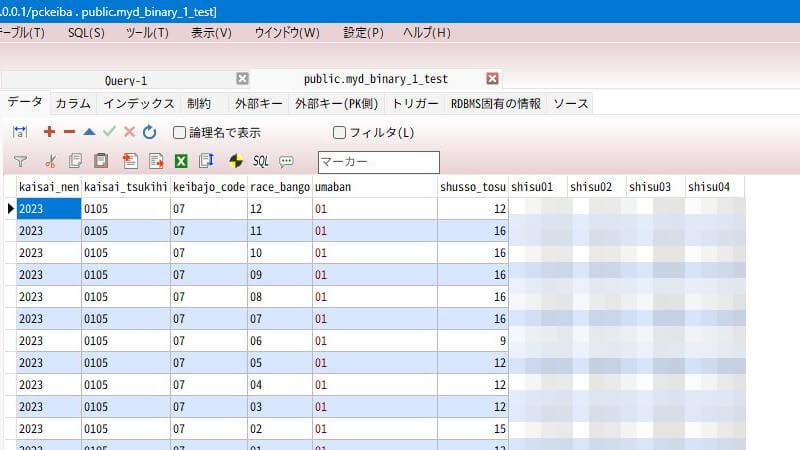
テーブル名は「myd_binary_1_test」にしました。
「Pythonデータ登録」画面の初期値と同じテーブル名です。
レースIDで予測するには
他の「AI競馬」の記事では、馬番情報に基づいた分析を行いました。しかし、今回はレースID(yyyymmddjjrr)で予測するという試みです。馬番情報の分析とは異なり、ちょっと工夫が必要です。
「Pythonデータ登録」画面は、テーブルに馬番の列が存在することを前提に設計してるので、ダミー値の馬番を設定する必要があります。
さらに、サンプルの予測用ソースコードは、テストデータが2行以上存在することを前提に設計しています。なので、ダミー値の馬番があるレースのレコードを2行作る必要があります。
レースIDで予測するには、同じレースIDで馬番が異なる、重複したレコードを2つ作ることが必要です。
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
予測(予想)させる
テストデータの準備が終わったら、次は「LightGBMによるAI競馬予想(Pythonデータ登録)」の記事にある「Pythonデータ登録画面の使い方」を参考に、LightGBMに予測させます。
- モデル(*.txt)
- 予測用ソースコード(*.py)
2つのファイルは二値分類の場合だと、こういう状態です。
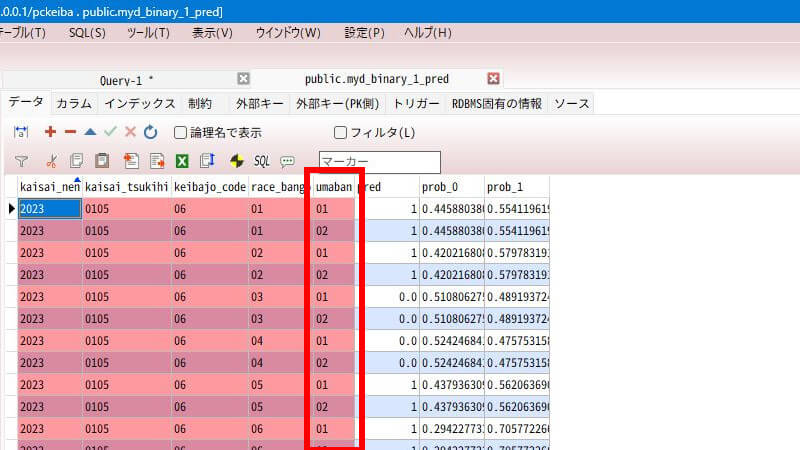
重複データの削除
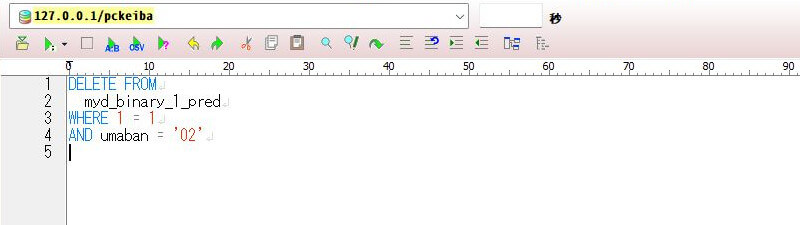
予測の処理が終わったら、予測データテーブル「myd_binary_1_pred」の重複データを削除します。SQLのDELETE文を使って、馬番違いで重複した2つあるうちの不要なレコードを1つ削除します。
シミュレーションする
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
SQLを作って、予測値テーブル「myd_binary_1_pred」を次のように集計してみました。結果は、
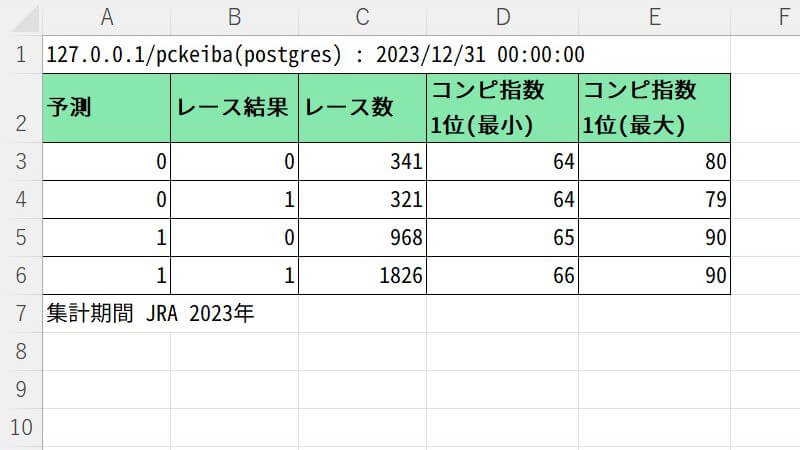
- 1 = コンピ指数1位馬が3着以内 的中率65%
- 0 = コンピ指数1位馬が4着以下 的中率52%
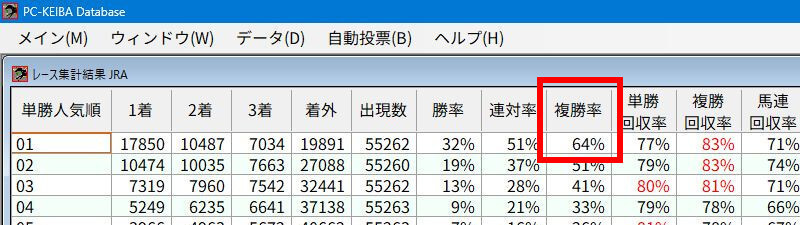
同じ集計期間における単勝1番人気の複勝率は64%なので、なかなか優秀な品質ではないでしょうか。
この機械学習モデルの強み
こんなもん、機械学習とか面倒くさいことせんでもコンピ指数の複勝率を集計して、しきい値でフィルターしたら同じちゃうんか、と思われるかもですが違います!
確かに、コンピ指数の複勝率だけでも、ある程度の成果は期待できます。しかし、この機械学習モデルは以下の点において、コンピ指数の単なる比較よりも優れた結果を生み出しています。
- 指数が同じ1位馬でも、異なる予測が可能
- 指数が高い1位馬でも凡走を予測し、的中
- 指数が低い1位馬でも好走を予測し、的中
以上の理由から、この機械学習モデルは、コンピ指数1位馬の信頼度を高い精度で判断できます。
さらに、二値分類の予測値(1 or 0)は、確率が50%以上の場合に1、それ未満の場合に0となります。この確率の値を活用することで、レースを3つ以上のカテゴリに分類したり、確率の高いレースのみを選んだりといった、さまざまな応用が可能になります。
