この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■SELECT文の基本
https://youtu.be/2GO9LCGzbkU
競馬予想プログラミングに関する記事を「投稿まとめ」で一覧にしてます。この記事は「自動投票」の一覧に含まれてます。一覧の順に読むとステップごとで分かりやすいです。
この記事では競馬予想の基本である基準タイムを作りながら、SQLの基本であるSELECT文を学習します。いきなり完成品を見せるのではなく、SELECT文を書くための順序と考え方を学ぶため、1つずつステップを踏みながら作ります。
SELECT文を制するものはSQLを制す
この格言は、管理人@PC-KEIBAが仕事で20年以上にわたり、SQLを書き続けて得た格言です。SQLは非常に多様な機能を持つため、全てを覚える必要はありません。代わりに、SELECT文に重点を置いて学習することをオススメします。なぜなら、SELECT文以外のSQLは一般的に使用頻度が高くないからです。そのため必要になった場合に、必要な情報をググれば十分です。
WHERE句を使って目的のレコードを自由に抽出できるようになれば、SELECT文の文法しか知らなくても「私はSQL書けます!」と自慢してOKです。UPDATE文やDELETE文も、SELECT文と同じWHERE句を知っていれば書けますから。
プログラミングに正解はない
そして、プログラミングが苦手な人や初心者の方によく見られる誤解の一つは、最初に学んだ方法が絶対的に正しいと思い込んでしまい、他の方法や考え方を探すことを諦めてしまうことです。
プログラムは料理と似ています。料理には正解のレシピが存在しませんよね?例えばカレーを作る場合、材料の種類や分量、煮込み時間などは個人の好みや自分の目指す味によって異なるものです。少しの違いがあっても、自分にとって美味しいなら問題ありません。
プログラミングも同じです。多くのお手本となる良いプログラムを調べながら、自分自身で試行錯誤し、経験を積んでいくことが大切です。失敗を恐れずに挑戦し、上達を目指してください。
SELECT文とは
「SELECT文」とは、世界共通のコンピューター言語である「SQL(エスキューエル)」の1種であり、データベース内のテーブルから必要なデータを取り出すためのコマンドです。SELECT文は機械学習モデルの作成においても必要不可欠です。
ちなみに、SQLには「標準SQL」という規格があり、一度覚えるとPostgreSQL以外のデータベースでも使うことができます。標準語と関西弁の違いみたいなもんですわ。
レコードの抽出条件を設定する
SELECT文の第1歩はレコードの抽出から。データベースの世界で「レコード」とは、行単位のデータを指します。今回は、
- JRAのレース
- 集計期間は2014年~2023年
- 集計値は1~5着馬の走破タイム
- ダートの良馬場
以上の条件で、基準タイムを集計することにします。
これが、条件を満たすレコードを抽出する最初のステップとしてのSELECT文です。
SELECT
se.soha_time
FROM
jvd_se se
WHERE 1 = 1
AND se.data_kubun = '7'
AND se.kaisai_nen >= '2014'
AND se.kaisai_nen <= '2023'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'SELECT文の「基本の基本」は、この3つの句で構成されます。
- SELECT句
- FROM句
- WHERE句
データベースがSELECT文を解析する順序
データベースがSELECT文を解析する時は、次の順序で解析しています。
- FROM句→どのテーブル見るの?
- WHERE句→レコードの抽出条件は?
- SELECT句→表示する項目は?
なので、人間がSELECT文を考えるときも同じ順序で書いていくと分かりやすいです。
FROM句
では、その順序に従ってFROM句に、見るテーブルを書きます。基準タイムを作成するにはレース結果の走破タイムのデータが必要です。JV-Data仕様書を調べると走破タイムは「馬毎レース情報」にあります。なので、FROM句にそのテーブル名「jvd_se」を書きます。
PC-KEIBA Databaseでは、JRA-VANのテーブル名を「"jvd_" + レコード種別ID」、地方競馬DATAのテーブル名を「"nvd_" + レコード種別ID」で統一しています。
テーブル仕様については、PC-KEIBAテーブル定義書を参照してください。
■PC-KEIBAテーブル定義書はこちら
PC-KEIBAテーブル定義書.zip (Excel版)
テーブル名の直後に書いてある(宣言している) "se" はSQLの世界で「別名(べつめい)」と呼びます。別名は、
- 重複する名前を分類するため
- その項目が、どのテーブルに属しているか明示するため
- 可読性、つまり人間がSQLを読みやすくするため
に使います。別名を宣言したらSQL内の項目が、どのテーブルに属しているのか「別名+"."(ピリオド)+項目名」の形で全て明示します。
ここでは別名を "se" にしていますが "t1" でも他でもかまいません。しかし、どのテーブルを指すのか一目で分かるほうが良いので、ここではレコード種別IDと同じ "se" にしています。
WHERE句
次はWHERE句に、レコードの抽出条件を書きます。まず「データ区分」を指定します。"7"は中央競馬の確定成績を表します。各項目と値の意味は「JV-Data仕様書」で調べながら書きます。開催年と確定着順の「範囲」はサンプルのように ">=" と "<=" の演算子でその範囲を指定します。
抽出条件を複数書く場合は「AND」でつなぎます。SQLは改行やインデント、大文字小文字の違いなど、書式にうるさくない言語ですが、サンプルのように式や項目を1行ずつ書いたほうが分かりやすくて修正も簡単です。
SQLにおける「インデント」とは、可読性を高めるための、行の先頭に挿入する、半角スペースによる段落です。
そして「WHERE 1 = 1」という書き方は、抽出条件の有無に関わらず、常にWHERE句の構文として成立させるための書き方です。管理人@PC-KEIBAは、この書き方を習慣にしています。こうすれば、式をコメントアウトするだけで抽出条件のオン・オフを簡単に切り替えることができ、データ検証する時とても便利です。なお、全てのレコードを取得するために抽出条件が不要な場合は、WHERE句の記述は不要です。
SQLの「コメントアウト」とは以下のように、通常、”–“(ハイフン2つ)でコメントアウトします。コメントアウトされたSQLは実行されず、SQLの説明やメモとしても利用できます。
WHERE 1 = 1
--AND se.data_kubun = '7'
AND se.kaisai_nen >= '2014'
AND se.kaisai_nen <= '2023'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'注意すべきポイントは、SQLが数値と文字列を異なるデータ型として扱うことです。そのため、それぞれに適切な方法で表現する必要があります。文字列型の項目に対する抽出条件では、値をシングルクォーテーションで囲む必要があります。数値型の項目に対する抽出条件では、値をそのまま書きます。
SELECT句
最後はSELECT句に、検索結果に表示する項目を書きます。今は、とりあえず走破タイムだけ。
SQLの実行結果はこのようになります。

テーブルの結合
前章で走破タイムを表示したものの、これだけでは、どのコースの走破タイムか分かりません。競馬場、芝・ダート、距離など、コースに関する情報が必要です。JV-Data仕様書を調べると、その情報は「レース詳細」にあるので、そこから取得して走破タイムと共に表示しましょう。
この他に、競走条件の項目と、ダートの良馬場という抽出条件をWHERE句に追加します。
SELECT
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_code
, se.soha_time
FROM
jvd_se se
INNER JOIN
jvd_ra ra
ON ra.kaisai_nen = se.kaisai_nen
AND ra.kaisai_tsukihi = se.kaisai_tsukihi
AND ra.keibajo_code = se.keibajo_code
AND ra.race_bango = se.race_bango
WHERE 1 = 1
AND se.data_kubun = '7'
AND se.kaisai_nen >= '2014'
AND se.kaisai_nen <= '2023'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'
AND ra.track_code >= '23'
AND ra.track_code <= '24'
AND ra.babajotai_code_dirt = '1'赤字の部分が今回追加した部分です。
SELECT句に複数の項目を書く場合は、カンマ(,)でつなぎます。「ON」のあとに複数の項目を書く場合は、WHERE句と同じく「AND」でつなぎます。
JOIN句
1つのSELECT文で2つ以上のテーブルを使う場合は、JOIN句にテーブルとテーブルの結合条件を書きます。テーブルの結合には、次の2つがあります。
- INNER JOIN (内部結合)
- LEFT JOIN (外部結合)
この他にもあるのですが、管理人@PC-KEIBAが仕事で20年以上にわたりSQLを書き続けて、この2つ以外の結合に出番はありませんでした。なので「結合はこの2つだけ」と覚えてください。今回は内部結合の「INNER JOIN」だけを使います。テーブルを3つ、4つと使いたい場合は、このJOIN句の下に同じように2つ目、3つ目のJOIN句を続けます。
キーでテーブルを結合する
そして、キーでテーブルを結合します。「キー」とはデータベースがテーブルのレコードを一意に識別するための項目です。主キー(しゅきー)と呼ぶ場合もあります。PC-KEIBA Databaseではレースを識別するキーを、次の4つの項目で定めています。言い換えると、この項目でレースを特定しています。
- kaisai_nen (開催年)
- kaisai_tsukihi (開催月日)
- keibajo_code (競馬場コード)
- race_bango (レース番号)
「レース詳細」と「馬毎レース情報」は、同じキー項目を持っているため、それぞれの項目がどのように紐づくのかをON句に書きます。ここで、先ほど登場した「テーブルの別名」が役に立つわけです。
SQLの実行結果はこのようになります。
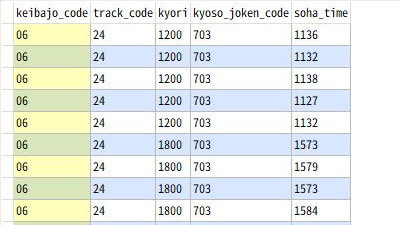
走破タイムを秒単位に変換する
今回の目的は、走破タイムの平均値を集計することです。JV-Data仕様書を調べると走破タイムは「9分99秒9で設定」の、4桁の文字列になっています。なので、関数を使って「4桁の文字列」を「秒単位の数値」に変換します。
SELECT
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_code
, to_number(substring(se.soha_time, 1, 1), '9') * 60
+ to_number(substring(se.soha_time, 2, 3), '999') / 10 AS soha_time
FROM
jvd_se se
INNER JOIN
jvd_ra ra
ON ra.kaisai_nen = se.kaisai_nen
AND ra.kaisai_tsukihi = se.kaisai_tsukihi
AND ra.keibajo_code = se.keibajo_code
AND ra.race_bango = se.race_bango
WHERE 1 = 1
AND se.data_kubun = '7'
AND se.kaisai_nen >= '2014'
AND se.kaisai_nen <= '2023'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'
AND ra.track_code >= '23'
AND ra.track_code <= '24'
AND ra.babajotai_code_dirt = '1'赤字の部分が今回変更した行です。この部分が何をやっているのかというと、次の手順で処理しています。
- 走破タイムの文字列を「分」と「秒」に切り出す。
- 切り出した「分」と「秒」の文字列をそれぞれ数値型に変換する。
- 合計して秒単位の数値型に変換する。(分×60)+(秒÷10)
- 式に別名を付ける。
これらの処理を順番に具体的に説明します。
substring で文字列を切り出す
まず、文字列を切り出すために substring を使います。「substring(サブストリング)」はPostgreSQLの関数です。
プログラムの世界で「関数(かんすう)」とは、渡された値を加工して返す、汎用的な部品のことです。
関数に渡す値を「引数(ひきすう)」、関数が返す値を「戻り値(もどりち)」と呼びます。この substring を使って、4桁の走破タイムを分と秒に分割します。
substringの書式は、
- substring(切り出す文字列, 切り出しを開始する位置, 切り出す長さ)
となっています。この仕様に従って切り出すと、分と秒はそれぞれ、
- substring(se.soha_time, 1, 1)→「9分99秒9で設定」の9分
- substring(se.soha_time, 2, 3)→「9分99秒9で設定」の99秒9
となるわけです。
to_number で数値型に変換する
次に、切り出した文字列を、to_number を使って数値型に変換します。「to_number」はPostgreSQLの関数で、文字列を数値型に変換します。この関数の書式は、
- to_number(変換する文字列, 書式)
となっています。この仕様に従って数値に変換すると、分と秒はそれぞれ、
- to_number(substring(se.soha_time, 1, 1), '9')
- to_number(substring(se.soha_time, 2, 3), '999')
となるわけです。substringの戻り値をto_numberで数値に変換しています。「書式」の部分には文字列の桁数分を "9" で埋めます。なぜ?と言うよりも、これがPostgreSQLのルールなんだと覚えてください。
合計して秒単位の数値型に変換する
そして、to_number の戻り値を加工して秒単位の数値に仕上げます。
- to_number(substring(se.soha_time, 1, 1), '9') * 60
- to_number(substring(se.soha_time, 2, 3), '999') / 10
赤字が加工した部分です。この、分と秒を足し算して「秒単位の走破タイム」は完成です。
式に別名を付ける
最後に、関数で編集した式に「AS」を使って、検索結果に対して別名を付けています。別名を付けない場合は、式がそのまま列名になります。それでは見た目が良くないでしょ?なので、ここでは元の項目と同じ「soha_time」という別名を付けています。「AS」は省略可能ですが可読性を高めるため、管理人@PC-KEIBAはいつもこの書き方を習慣にしています。
to_number(substring(se.soha_time, 1, 1), '9') * 60
+ to_number(substring(se.soha_time, 2, 3), '999') / 10 AS soha_timePC-KEIBA Database のテーブルが全て文字列型の理由
こんな面倒くさいことするより初めから秒単位の、数値型の項目にしとけよ、と思うでしょう。しかし、大量のレコードを格納するデータベースでは固定長文字列という形式が、さまざまな場面で有利なんです。そのため、PC-KEIBA Databaseのテーブルは全て文字列型の項目で設計しています。システムの世界によくあるトレードオフです。
SQLの実行結果はこのようになります。
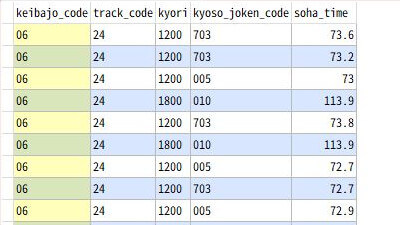
グループ化して集計する
いよいよ走破タイムの平均値を集計します。赤字の部分が今回追加した部分です。
SELECT
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_code
, avg(to_number(substring(se.soha_time, 1, 1), '9') * 60
+ to_number(substring(se.soha_time, 2, 3), '999') / 10) AS soha_time
FROM
jvd_se se
INNER JOIN
jvd_ra ra
ON ra.kaisai_nen = se.kaisai_nen
AND ra.kaisai_tsukihi = se.kaisai_tsukihi
AND ra.keibajo_code = se.keibajo_code
AND ra.race_bango = se.race_bango
WHERE 1 = 1
AND se.data_kubun = '7'
AND se.kaisai_nen >= '2014'
AND se.kaisai_nen <= '2023'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'
AND ra.track_code >= '23'
AND ra.track_code <= '24'
AND ra.babajotai_code_dirt = '1'
GROUP BY
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_codeGROUP BY句
まずGROUP BY句に、グループ化する項目を宣言します。ここでは前章までの結果を、
- 競馬場コード
- トラックコード
- 距離
- 競走条件コード
のグループに分類して走破タイムの平均値を求めます。
グループ化のイメージ
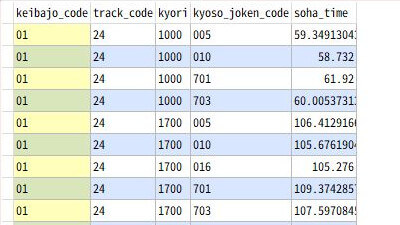
データベースの内部では、次のような流れで処理しています。まず、GROUP BY句で宣言した項目の値が同じレコードを並べてグループ化します。ここでは下図の赤い囲み線と、青い囲み線がそれぞれ「同じグループ」です。その同じグループを1行にまとめて・・
グループ化する前の実行結果
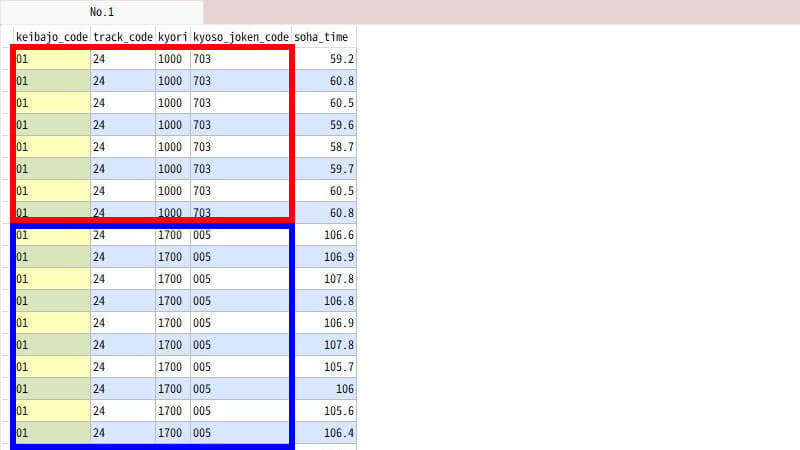
avg 関数が soha_time の平均値を集計するわけです。
グループ化した後の実行結果
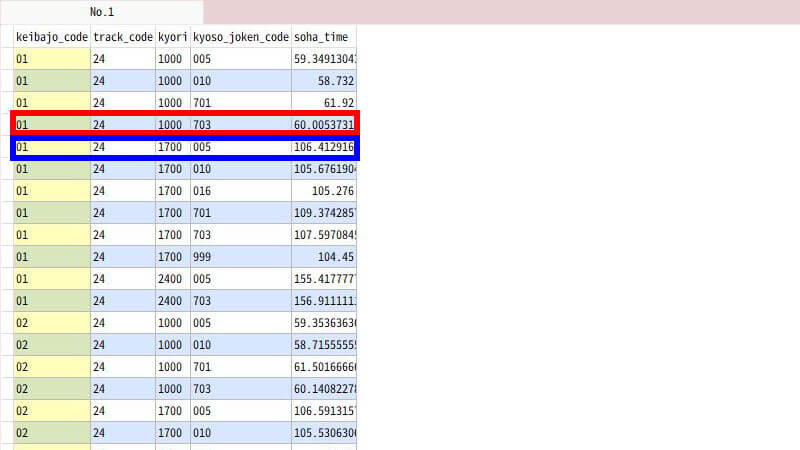
今回は平均値を返すSQLの集計関数「avg」を使いました。これ以外にSQLの集計関数には、
- sum (合計値を集計する)
- max (最大値を取得する)
- min (最小値を取得する)
- count (レコード数を取得する)
が、あります。
検索結果の並べ替え
最後は、検索結果を見やすく整理するためにレコードの並び順を指定します。
SELECT
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_code
, avg(to_number(substring(se.soha_time, 1, 1), '9') * 60
+ to_number(substring(se.soha_time, 2, 3), '999') / 10) AS soha_time
FROM
jvd_se se
INNER JOIN
jvd_ra ra
ON ra.kaisai_nen = se.kaisai_nen
AND ra.kaisai_tsukihi = se.kaisai_tsukihi
AND ra.keibajo_code = se.keibajo_code
AND ra.race_bango = se.race_bango
WHERE 1 = 1
AND se.data_kubun = '7'
AND se.kaisai_nen >= '2013'
AND se.kaisai_nen <= '2024'
AND se.kakutei_chakujun >= '01'
AND se.kakutei_chakujun <= '05'
AND ra.track_code >= '23'
AND ra.track_code <= '24'
AND ra.babajotai_code_dirt = '1'
GROUP BY
ra.keibajo_code
, ra.track_code
, ra.kyori
, ra.kyoso_joken_code
ORDER BY
ra.keibajo_code ASC
, ra.track_code ASC
, ra.kyori ASC
, ra.kyoso_joken_code ASCORDER BY句
赤字の部分が今回追加した部分です。検索結果の並び順を指定するには「ORDER BY句」を使います。ここでは、次の順序で並べ替えしています。
- 競馬場コードの昇順
- トラックコードの昇順
- 距離の昇順
- 競走条件コードの昇順
並び順は項目のあとに、
- ASC (昇順→小さい順)
- DESC (降順→大きい順)
の、いずれかを指定します。ただし、今回の並べ替えはGROUP BY句と同じ内容なので、ORDER BY句なしでも結果は同じです。
SQLの実行結果はこのようになります。以上で、基準タイムは完成です。
このSQLをベースにして、抽出条件を変更したり自由にカスタマイズしたりできます。最初のカレーの話と同じ考え方ですね。
SELECT文の基本のまとめ
SELECT文は、次の6つの句で構成されています。
- SELECT句→表示する項目は?
- FROM句→どのテーブル見るの?
- JOIN句→テーブルの結合は?
- WHERE句→レコードの抽出条件は?
- GROUP BY句→グループ化する項目は?
- ORDER BY句→並べ替えの項目は?
この他に、集計関数の演算結果でフィルターする「HAVING句」がありますが、出番はあまり無いです。なので、必要になるまで知らなくて良いです。ほとんどのSELECT文は上記の「6つの句」だけで出来ています。


コメント