
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■競馬予想AIの開発がはかどるPythonのソースコード
https://youtu.be/HSXkCLDoge0
競馬予想AIの開発がはかどるPythonのソースコード
この記事を読む前に、次の記事を先に読んでください。その中には、機械学習の基礎知識や、学習データで使う説明変数の内容など、他のデータ分析方法と共通する説明が含まれています。
学習用ソースコード (Development Ver.)
ここに公開するPythonのソースコードを使えば、特徴量選択とハイパーパラメータのチューニングが一度にできて、機械学習モデルの開発がすごくはかどります。
基本の学習用ソースコードに「Boruta」と「Optuna」の実装を統合したものです。時間をかけて作った説明変数が「Boruta」にバッサリ捨てられたときは悲しいですが(笑)
さらに、引数で学習データを指定できるので、複数の機械学習モデルをまとめて作ることもできます。
今回の例では、「二値分類」を使いますが、ハイパーパラメータや評価指標の部分を修正すれば、「多クラス分類」や「回帰分析」にも応用できます。各分析方法の記事でソースコードの差異を確認して、必要に応じて修正してください。
この学習用ソースコードのファイル名は「binary_train_development.py」とします。
学習用ソースコード
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、この記事の最後の、有料会員限定のダウンロードリンクからも、ファイルをダウンロードできます。
import matplotlib.pyplot as plt
import numpy as np
import optuna.integration.lightgbm as lgb
import os
import pandas as pd
import sys
np.float = float
np.int = int
from boruta import BorutaPy
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.model_selection import train_test_split
# CSVファイル読み込み
in_file_name = sys.argv[1]
df = pd.read_csv(in_file_name, encoding='SHIFT_JIS')
# 説明変数(x)と目的変数(y)を設定
target = 'target'
x = df.drop(target, axis=1).values # y以外の特徴量
y = df[target].values
# 訓練データとテストデータを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# Borutaによる特徴量選択
estimator = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
feature_selector = BorutaPy(estimator=estimator, n_estimators='auto', random_state=0, verbose=2, alpha=0.05, max_iter=100)
feature_selector.fit(x_train, y_train)
x_train = feature_selector.transform(x_train)
x_test = feature_selector.transform(x_test)
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error', # 評価指標 : 正答率
'num_boost_round':100
}
# モデルの学習
train_set = lgb.Dataset(x_train, y_train)
valid_sets = lgb.Dataset(x_test, y_test, reference=train_set)
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets, num_boost_round=100)
# モデルをファイルに保存
fname = os.path.splitext(in_file_name)[0]
fname = fname + '_model.txt'
model.save_model(fname)
# テストデータの予測
y_prob = model.predict(x_test)
y_pred = np.where(y_prob < 0.5, 0, 1)
# 評価指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
# 評価指標をファイルに保存
fname = os.path.splitext(in_file_name)[0]
fname = fname + '_score.txt'
with open(fname, mode='w') as f:
f.write('正解率 = ' + str(accuracy) + '\n')
f.write('適合率 = ' + str(precision) + '\n')
f.write('再現率 = ' + str(recall) + '\n')
# 特徴量重要度
importance = np.array(model.feature_importance())
selected_features = feature_selector.support_ # Borutaによって選択された特徴のインデックス
feature = df.drop(target, axis=1).columns[selected_features]
df = pd.DataFrame({'feature':feature, 'importance':importance})
df = df.sort_values('importance', ascending=True)
n = len(df) # 説明変数の項目数を取得
values = df['importance'].values
plt.barh(range(n), values)
values = df['feature'].values
plt.yticks(np.arange(n), values) # x, y軸の設定
# 特徴量重要度をファイルに保存
fname = os.path.splitext(in_file_name)[0]
fname = fname + '_model.png'
plt.savefig(fname, bbox_inches='tight', dpi=500)Development Ver.の使い方
前提条件
前提条件として、次の記事で紹介しているPythonのライブラリが全てインストールされていることが必要です。
py -m pip install pandaspy -m pip install scikit-learnpy -m pip install lightgbmpy -m pip install matplotlibpy -m pip install optunapy -m pip install optuna-integrationpy -m pip install borutaインストール済みライブラリの一覧を確認するには、次のコマンドを使えばOK。
pip list
作業用フォルダを作る
今回の例では、Cドライブの直下に「pckeiba」というフォルダを作って作業することにします。
学習データを作る
今回の例では、「二値分類」の記事で公開している学習データを、芝とダートに分類してみます。
SQLファイルをコピーする
学習データ作成用のSQLファイル「binary_train.sql」をコピーします。「pckeiba」のフォルダはこういう状態です。2つのファイルを置きます。
SQLファイルの名前を変更する
今回の例では、SQLファイルの名前をそれぞれ次のように変更して作業を進めます。
- binary_train_dirt.sql
- binary_train_shiba.sql
ファイル名は、自分が分かりやすい名前にすれば何でもOKです。
SQLに抽出条件を追加する
オリジナルの学習データを作る場合は、この節は読み飛ばしてください。必要な学習データの分だけSQLを用意すればOKです。
SQLファイルをサクラエディタで開いて、それぞれの抽出条件を追加します。
ダート(binary_train_dirt.sql)の場合は、次のように抽出条件を追加します。
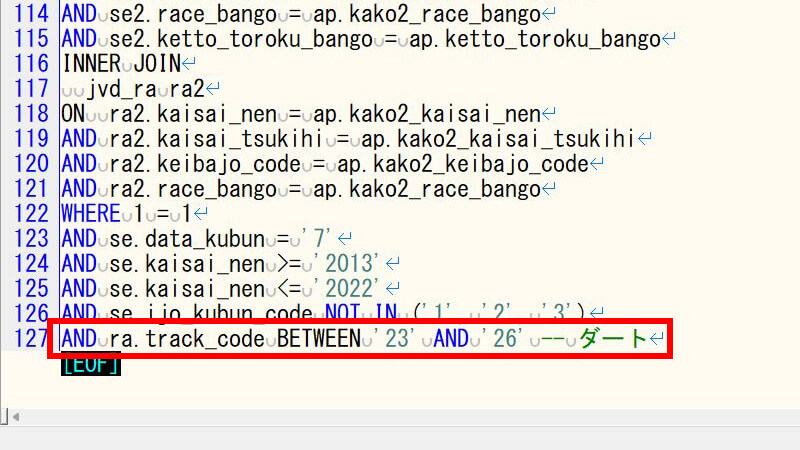
芝(binary_train_shiba.sql)の場合は、次のように抽出条件を追加します。
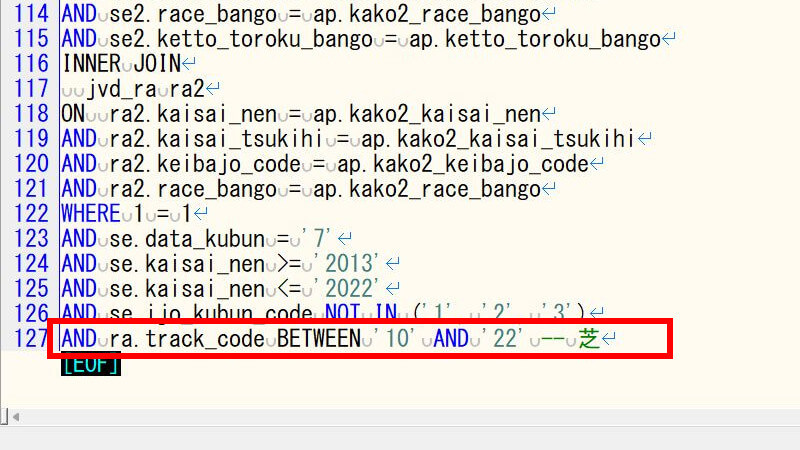
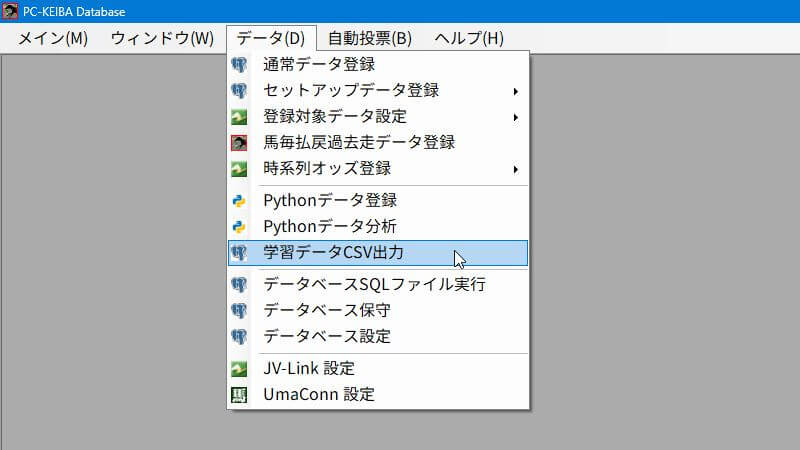
学習データCSVを出力する
「学習データCSVを出力する」のマニュアルの手順に従って、「学習データCSV出力」画面で学習データCSVを出力します。
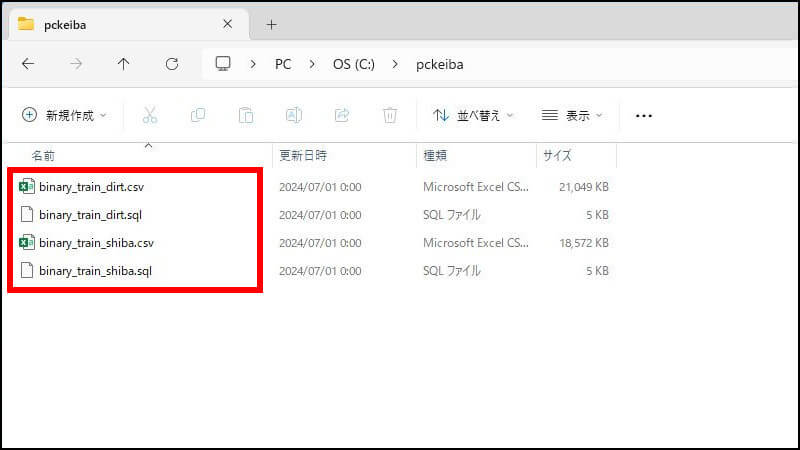
2つの学習データCSVを出力したら、「pckeiba」のフォルダはこういう状態です。4つのファイルがあります。
- 学習データ(binary_train_dirt.csv)
- SQLファイル(binary_train_dirt.sql)
- 学習データ(binary_train_shiba.csv)
- SQLファイル(binary_train_shiba.sql)
学習データCSVを出力したら、SQLファイルはもう必要ないので別の場所に移動してください。
バッチファイルを作る
その後、「pckeiba」フォルダに学習用ソースコードを置きます。すると、フォルダはこういう状態です。3つのファイルがあります。
- 学習用ソースコード(binary_train_development.py)
- 学習データ(binary_train_dirt.csv)
- 学習データ(binary_train_shiba.csv)
ファイルパスのコピー
Ctrl+A(全選択)でフォルダ内のファイルを全選択。その状態で、Ctrl+Shift+C(パスのコピー)でフォルダ内のファイルのパスをコピーします。
次に、サクラエディタを起動して貼り付け(Ctrl+V)ましょう。
ファイル名の一覧を作る
学習用ソースコードのファイル名の、前のパスを選択(Shift+Home)して、こういう状態にして、コピー(Ctrl+C)します。
コピーしたパスをファイル名だけに変更します。次の手順で作業します。
- Ctrl+R(置換)でダイアログを起動
- 「置換前」にコピーしたパスを貼り付け(Ctrl+V)
- 「置換後」を空白にする
- 「すべて置換」ボタンをクリック
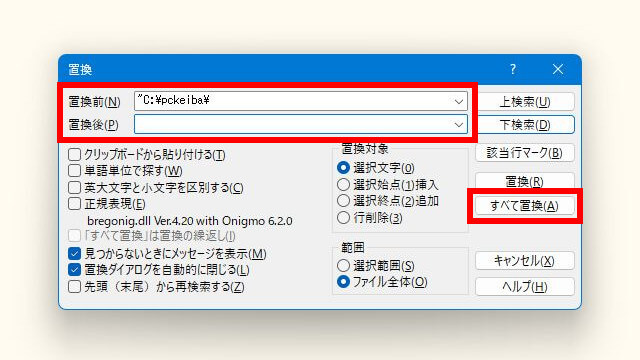
後ろのダブルクォーテーションも不要なので、同じ要領ですべて置換します。これでファイル名の一覧ができました。
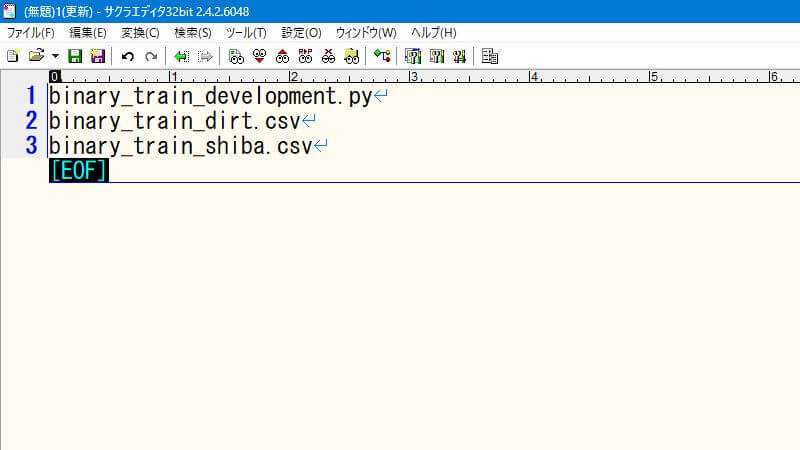
コマンドを作る
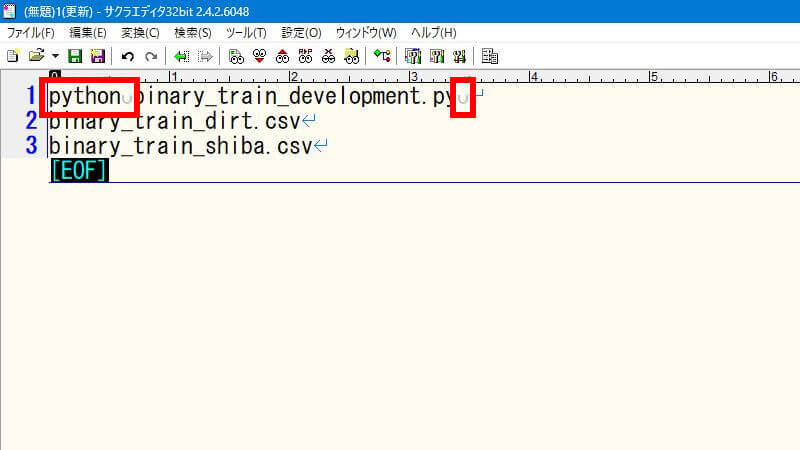
次に、学習用ソースコードのファイル名の先頭に「python」と半角スペースを追加します。ファイル名の後に半角スペースを追加します。こういう状態です。
最後に、正規表現を使って仕上げをします。直前に編集したテキストを切り取って、学習データのファイル名の前に貼り付けます。手順は次のとおりです。
- 1行目を全選択して切り取り(Ctrl+X)
- Ctrl+R(置換)でダイアログを起動
- 「置換前」にキャレット(^)を入力
- 「置換後」に切り取りしたコマンドを貼り付け(Ctrl+V)
- 「正規表現」にチェック
- 「すべて置換」ボタンをクリック
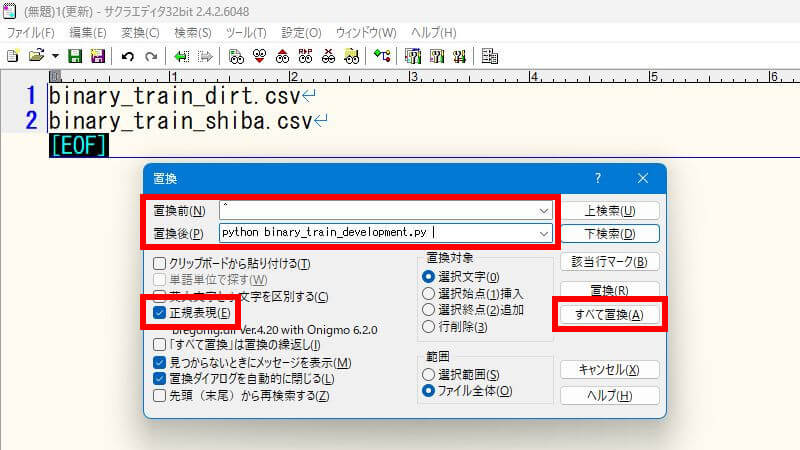
すると、こういう状態になります。コマンドの意味を説明すると、引数で学習データのファイル名を渡して、学習用ソースコードを実行します。
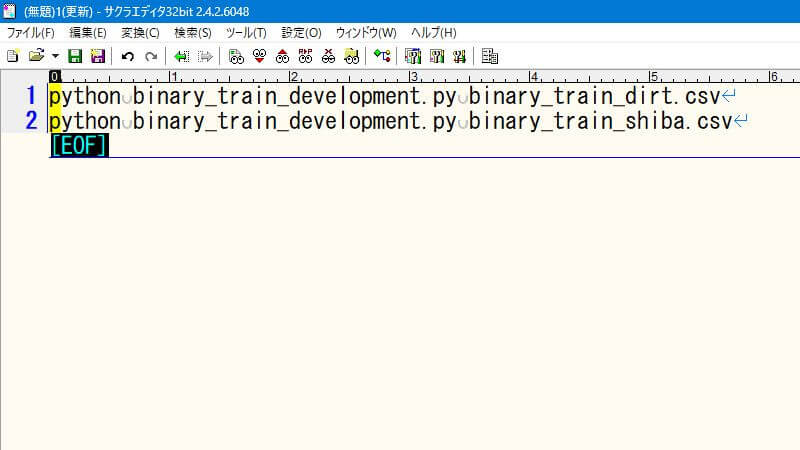
バッチファイルの保存
このファイルを「binary_train_development.bat」という名前で保存(Ctrl+S)します。これでバッチファイルが完成しました。
学習用ソースコードのファイル名と違うのは拡張子だけです。バッチファイルの名前は何でも良いんですが、直感的に分かりやすいのでこうしました。
LightGBMに学習させる
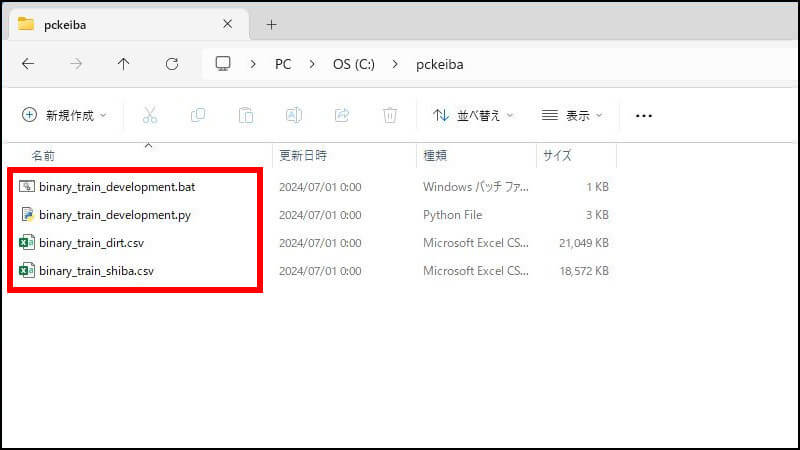
ここまでの手順を進めると、「pckeiba」のフォルダはこういう状態です。4つのファイルがあります。
- バッチファイル(binary_train_development.bat)
- 学習用ソースコード(binary_train_development.py)
- 学習データ(binary_train_dirt.csv)
- 学習データ(binary_train_shiba.csv)
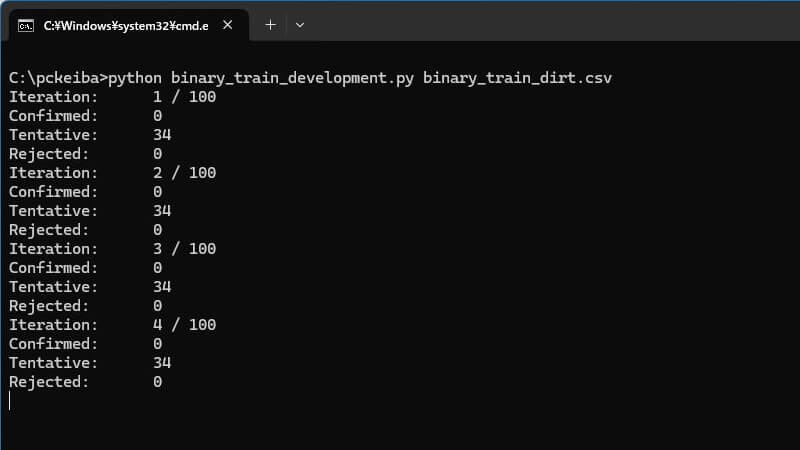
バッチファイルの実行
バッチファイルをダブルクリックして、学習用ソースコードを実行します。すると、LightGBMが学習を開始します。まず、「Boruta」が特徴量選択を行います。
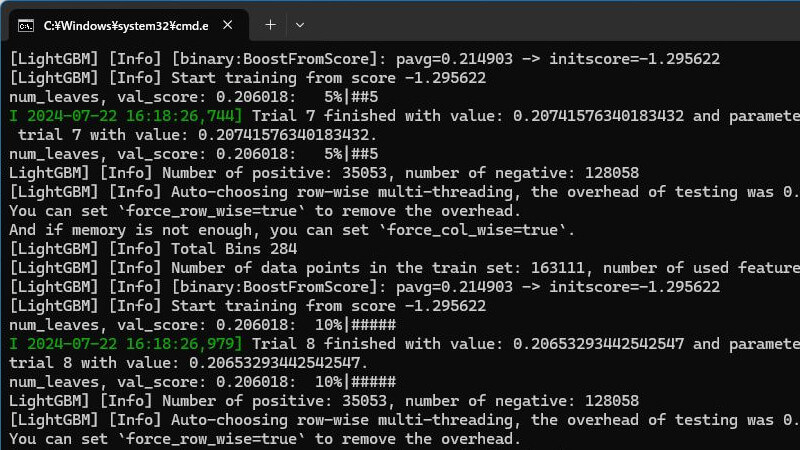
その次に、「Optuna」がハイパーパラメータのチューニングを行います。
処理が終わるとコマンドプロンプトが自動的に閉じます。
出力されるファイル
1つの学習データに対して、次の3つのファイルが出力されます。それぞれのファイルの意味は次の通りです。
- *_model.png→特徴量重要度
- *_model.txt→機械学習モデル
- *_score.txt→評価指標
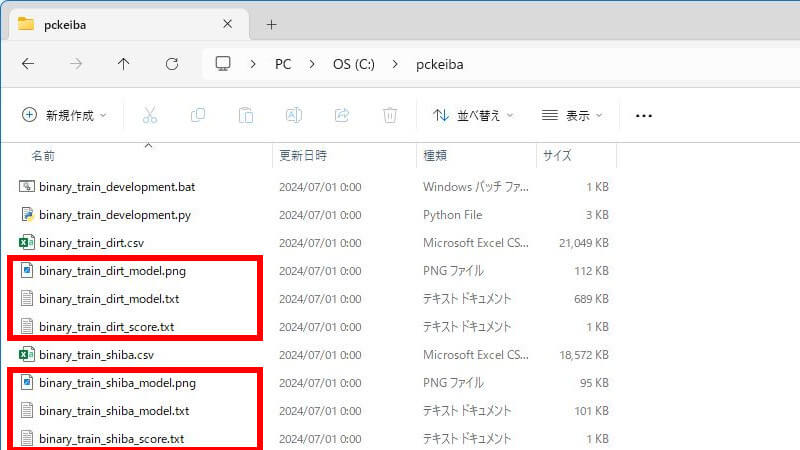
特徴量重要度を見て、特徴量選択の結果を確認します。評価指標を確認して、モデルの品質に納得するまで繰り返します。
完成したら、機械学習モデルを使って予測させます。予測のやり方は「二値分類」の記事を参考にしてください。
では「PC-KEIBA Database」を活用して、AI競馬予想を思う存分楽しんでください!

