
この記事では「LightGBMによるAI競馬予想(準備編)」で紹介した、予測用ソースコードの実行をソフトが全レース自動でやる機能、「Pythonデータ登録」画面について説明します。さらに予測値と確率のデータをテーブルに登録するのが目的です。
作業のおおまかな流れ
「Pythonデータ登録」画面を使うための、作業のおおまかな流れを説明します。
「Pythonデータ登録」画面は有料会員限定の機能です。有料会員については「会員について」のマニュアルで解説しているので参考にして下さい。
データの分析方法を決める
「LightGBMによるAI競馬予想(準備編)」の記事を読んでデータ分析の方法を決めてください。そしたら決めた分析方法の、
- 出馬表データを作る
- LightGBMに学習させる
までやってください。ここでは「ランキング学習」を例に説明します。
出馬表データを作る
予測させる出馬表データはイチから作るのではなく「LightGBMによるAI競馬予想(準備編)」で紹介した学習データに「レースID」と「馬番」を加えるだけのSQLです。これにはSELECT文の結果で新しいテーブルを作るSQLを使います。
今回の出馬表データはCSVファイルじゃなくてデータベースのテーブルに保存します。
CREATE TABLE table_name AS
SELECT~このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
そうすると、こんな感じのテーブルが出来上がります。説明変数の前に、主キーの「レースID」と「馬番」を加えてます。
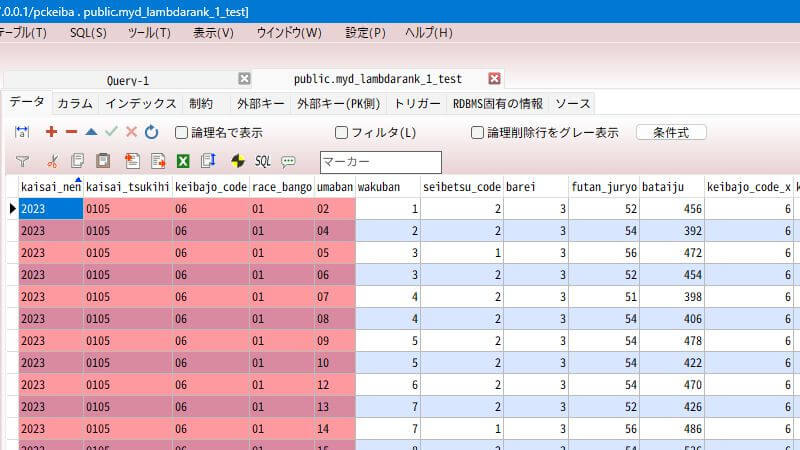
テーブル名は「myd_lambdarank_1_test」にしました。試作の出馬表データを複数作って比較を繰り返すことを考えて、
- myd_lambdarank_1_test
- myd_lambdarank_2_test
- myd_lambdarank_3_test
と、こんな感じで番号をつけることを想定してます。
「Pythonデータ登録」画面の初期値も同じにしてます。
Pythonデータ登録のルール
Pythonデータ登録のルールは次の2つです。
- 出馬表データのルール
- 出力するファイル名のルール
サンプルのソースコードそのままでイケる内容なので、特に気にする必要はありません。
出馬表データのルール
出馬表データのテーブルに欠損値(null)が存在しないようにしてください。サンプルのSQLのように「coalesce」関数を使えばOK。coalesceの使い方はググればOK。
出力するファイル名のルール
予測用ソースコード(*.py)が出力する予測値と確率のファイル名は次のルールで。サンプルの予測用ソースコードそのまんまでOK。
- レースID(※1) + “_pred.csv”
- レースID(※1) + “_prob.csv”
| (※1)レースID | 年月日場R yyyymmddjjrr(12桁) |
|---|
ユーザーが出力するファイル名をカスタマイズすることは無いと思うけど念のため。
Pythonデータ登録画面の使い方
ファイルの準備
2つのファイルを準備します。今回の例では「pckeiba」というフォルダに、
- モデル(*.txt)
- 予測用ソースコード(*.py)
2つのファイルを置きます。ランキング学習の場合だと、こういう状態です。
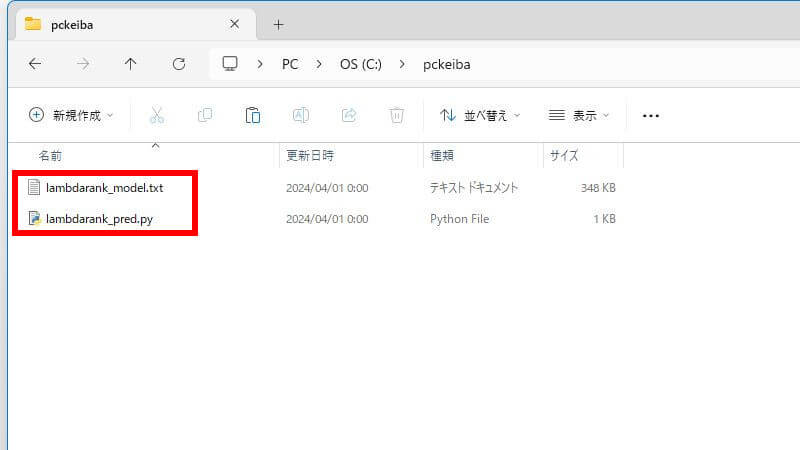
フォルダのパスに全角文字が含まれると、予測データが登録できません。半角文字のみを使用したパスに、ファイルを置いてください。
モデルと予測用ソースコード以外のファイルをここに置かないでください。ソフトがここに色んなファイルを作ったり削除したりするので、上書きとか削除されたりする可能性があります。
「Pythonデータ登録」画面の表示
- ツールバーの「データ」をクリックします。
- メニューの「Pythonデータ登録」をクリックします。
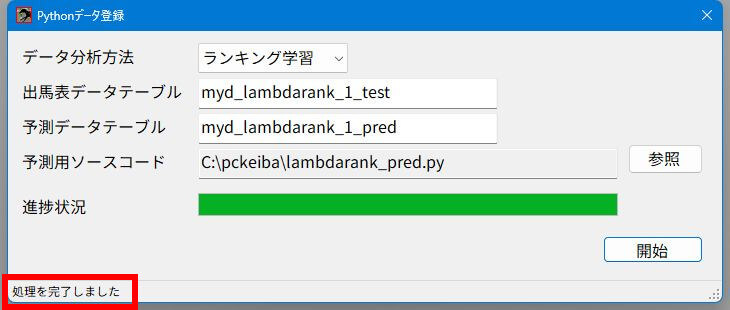
「Pythonデータ登録」画面に必要な情報を入力します。
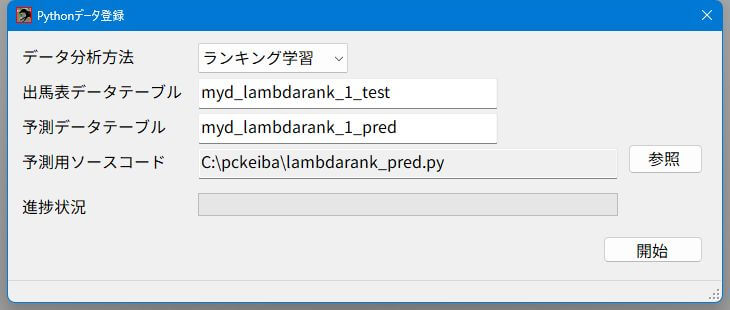
- 「データ分析方法」を選択。
- 「出馬表データテーブル」は先の「レースID」と「馬番」を加えたSQLであらかじめ作っておいたもの。
- 「予測データテーブル」はこの名前でソフトが作るもの。
- 「予測用ソースコード」は右側の「参照」ボタンで選択します。
「予測データテーブル」は毎回、テーブルを削除→新規作成します。
命名規則に違反するテーブル名を使うと実行時、エラーになります。PostgreSQLの命名規則はググってください。まあ、ググらんでも普通に命名すればOK(笑)
準備できたら画面右下の「開始」ボタンをクリックします。
予測(予想)させる
ソフトがレース単位で予測用ソースコードを実行してくれます。処理が終わったらこの画面は自動的に閉じるので、しばらく待ってください。
レース数によっては、かなり時間がかかる処理です。そのため、最初は1日分の少量でテストを行うことをオススメします。問題なく動作することを確認してから、寝る前とか、お出かけ前に実行しておくのがオススメです。
画面左下に「処理を完了しました」が表示されたら、画面右上の閉じるボタン「✕」をクリックします。
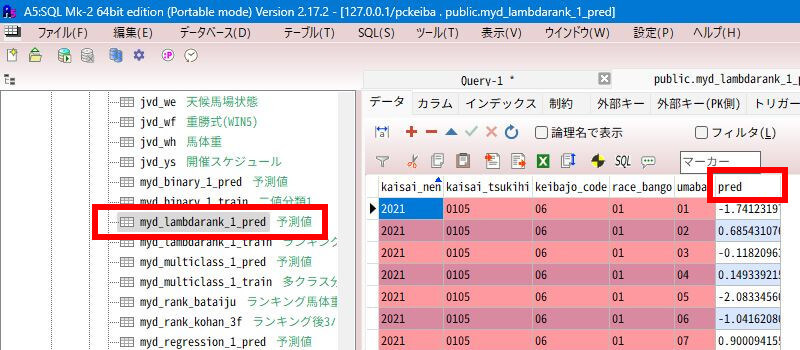
予測データテーブルを見る
「A5:SQL Mk-2」で画面左側の「テーブル」のツリーを展開します。「Pythonデータ登録」画面で指定した名前の予測データテーブルが出来てることを確認します。
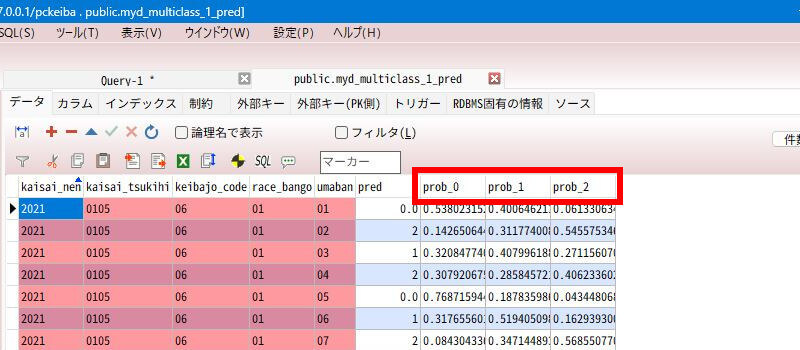
「二値分類」と「多クラス分類」の場合は、確率の項目「prob_*」もあります。
予測データテーブルが見つからない場合
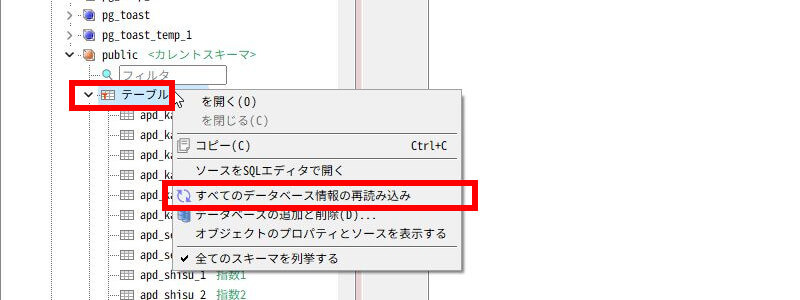
次の手順で「A5:SQL Mk-2」を再読み込みしてください。
- 画面左側の「テーブル」のツリーを右クリック。
- 「すべてのデータベース情報の再読み込み」をクリック。
シミュレーションする
あとはこの予測データテーブルを使ってシミュレーションします。
シミュレーションについては「LightGBMによるAI競馬予想(シミュレーション編)」の記事で解説しているので参考にして下さい。
「多クラス分類」のクラス数について
クラス数は、目的変数の分類数と一致する必要があります。例えば、目的変数を0から3までの範囲で分類した場合、クラス数は「4」となります。
必要な場合は修正してください。詳細は「多クラス分類」の記事をご覧ください。

