
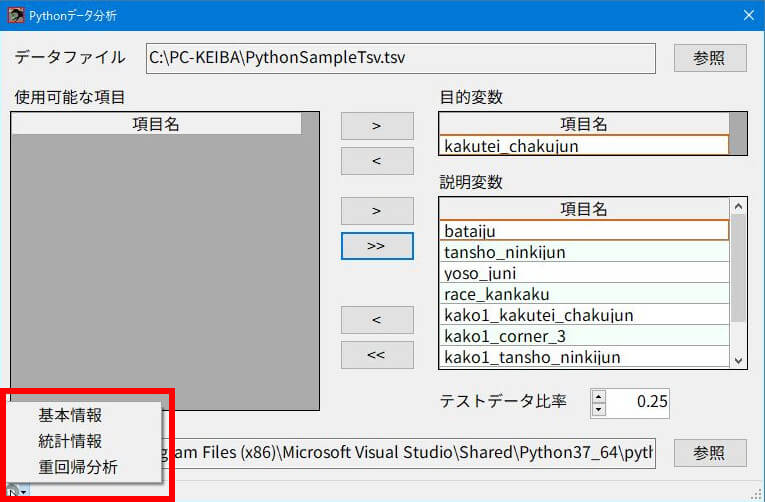
この画面はPythonのプログラミング知識がないユーザーでも、一般的なWindowsデザインの画面でpandasの機能を簡単に使えるようにしたものです。データファイルの内容が回帰分析のために整備されたものであれば、競馬のデータ分析以外にも使えます。
Pythonデータ分析画面を使う前に、
・Pythonデータ分析画面を使う準備
が必要です。
Pythonデータ分析
「Pythonデータ分析」画面の表示
- ツールバーの「データ」をクリックします。
- メニューの「Pythonデータ分析」をクリックします。
データファイルの選択
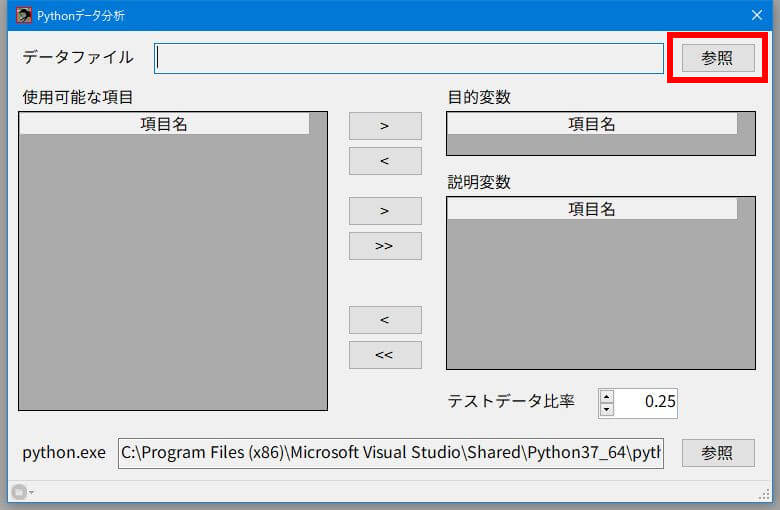
画面右上の「参照」ボタンをクリックすると「ファイルを選択してください」のダイアログボックスが出てきます。ここで目的の場所(フォルダ)へ移動して、分析するデータファイルを選択します。
ここでは前ページの「Pythonデータファイルの作り方」で作ったデータファイルを使ってみます。
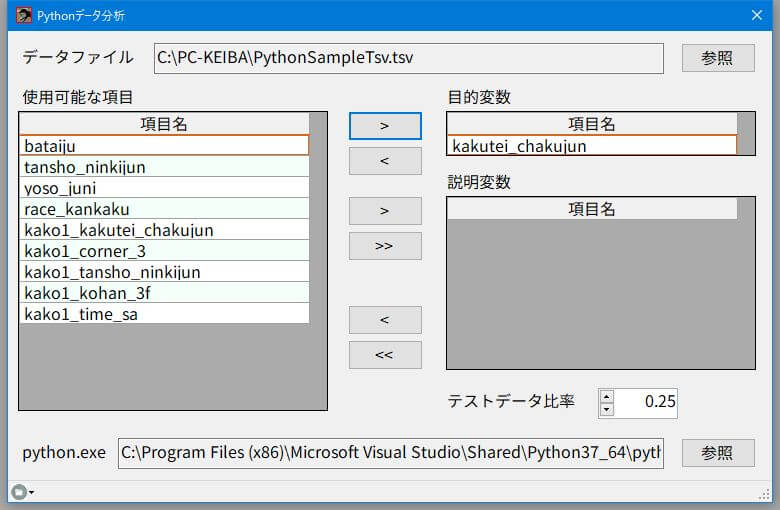
表示するファイル(CSVまたはTSV)を切り替えるには、画面右下にあるリストボックスで表示する拡張子を切り替えてください。
目的変数・説明変数
画面左の「選択可能な項目」から「>」で1つ移動。「>>」ですべて移動します。目的変数は1つしか選択できません。
テストデータ比率
0.1~0.5(10%~50%)の範囲で設定できます。一般的には0.25~0.3の数字を採用します。画面の初期値は「0.25」を設定しています。保存はできないのでその都度、設定してください。
メニュー
画面左下の小さなボタンをクリックするとメニューを表示します。各画面の内容は「CSV」または「TSV」ファイル形式で出力できます。
Pythonの実行中は、黒い画面(コマンドプロンプト)を表示します。自動的に閉じるので、そのまま少し待ってください。
各画面の内容はpandasのバージョンアップで仕様変更があった場合、正しく表示されなくなる可能性があります。PC-KEIBA Databaseでは、その都度対応します。
基本情報
このメニューでは、pandasの「DataFrame.info()」を実行します。
- データにnull値は存在するか?
- Pythonが各項目のデータ型をどう解釈するか?
を確認したいとき使う機能です。しかし競馬のデータ分析ごときで、この機能に出番は無いと思ってます。なぜなら目的変数、説明変数、SQLを設計した時点で予想外が無いよう考慮しておくべきです。必要な人だけ使ってください。
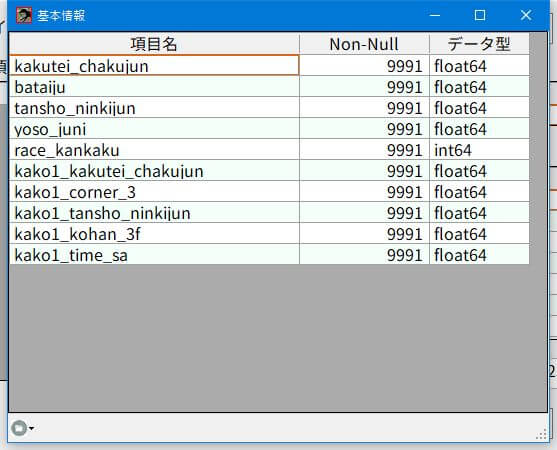
基本情報はデータファイルの選択だけで表示できます。
統計情報
このメニューでは、pandasの「DataFrame.describe(include=’all’)」を実行します。次の9つの情報を表示します。このあたりの難しいことは専門家が書いた統計学の本や、賢い人のサイトを参考に学習して下さい。
- データ型
- データ数
- 平均値
- 標準偏差
- 最小値
- 第1四分位数
- 中央値
- 第3四分位数
- 最大値
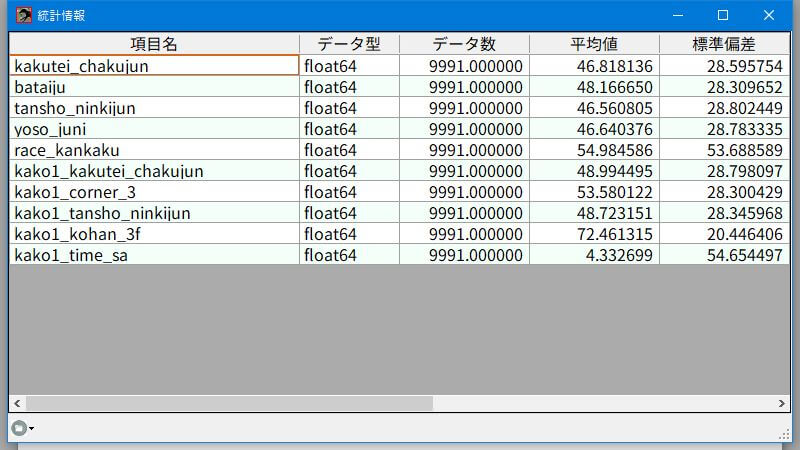
統計情報はデータファイルの選択だけで表示できます。
基本情報と統計情報で「データ型」の内容が一致しない場合がありますが、pandasの出力結果をそのまま表示しているだけなので、PC-KEIBA Databaseのバグではありません。
重回帰分析
「重回帰分析」は有料会員限定のメニューです。有料会員については「会員について」のマニュアルで解説しているので参考にして下さい。
この機能を目的に有料会員の新規登録を希望する方は「基本情報」または「統計情報」の画面を表示して、Pythonが期待通りに動作するか、つまりこのマニュアルと同じになるかテストしてからお申し込みください。
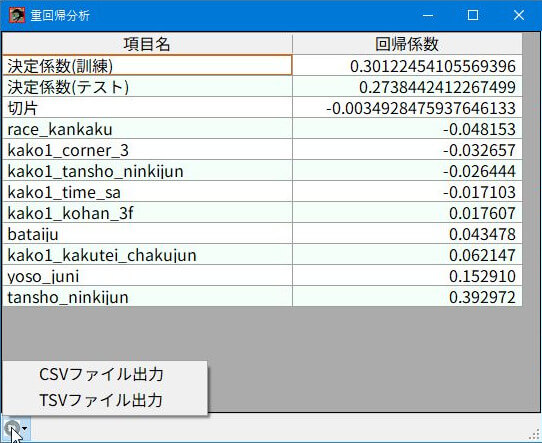
この画面のデザインは少し紛らわしいですが、1~3行目が上から順に、
- ※回帰係数の列がそれぞれの値
- 決定係数(訓練)
- 決定係数(テスト)
- 切片
4行目以降が、
- 各項目に対する回帰係数
となってます。
管理人@PC-KEIBAはパソコンを始めたばかりの昔、何万円もするExcelのアドインとか買って同じことをコツコツやってたんですが、今はこんな簡単にデータ分析できるプログラムが無料で手に入ります。いやぁ~、ほんまスゴい時代になったもんですよ。
PC-KEIBA Databaseの「Pythonデータ分析」のマニュアルは以上で終了です。思う存分、Pythonのデータ分析を楽しんでください!

