
ここでは、当サイトが推奨するSQLエディタ「A5:SQL Mk-2」で、Pythonデータ分析に使うデータファイルの作り方を説明します。
回帰分析の知識や手法、ウンチクはここでは語りません。このページはあくまで「PC-KEIBA Database」のマニュアルです。知らない単語が出てきたらググってください。データ分析に決まりはありません。ここで紹介するのは一例です。統計学の本などを参考にして、最終的には自分流のやり方を確立してください。今回使用するデータはあくまでマニュアル用、つまり画面の使い方を説明するために都合が良いデータです。なので、こんな内容がデータ分析として有効なんか?儲かるんか?などと考えたり、ツッコミは無しでお願いします(笑)
データファイルのルール
まず、Pythonデータ分析で使うデータファイルのルールについて。
- ファイル形式はCSVまたはTSV。
- データに改行を含めない。
- 項目名のヘッダ行は必須。
- データを囲むダブルクォーテーションの有無は問わない。
- 文字コードはShift_JIS。
ここまではシステムの世界の一般的なルールと同じです。この他に、
- 項目名はユニーク(※重複なし)にする。
- 項目名は半角英数字にする。
「半角英数字」は絶対ではありませんが、そうしといたほうが他の開発にもいろいろ都合が良いです。なので、ぜひ習慣にしてください。
ちなみに「CSV」と「TSV」の違いは、データの区切り文字が「カンマ」か「タブ文字」か、の違いだけです。表計算ソフトでもよく使うためファイル形式は一般的に「CSV」が好まれますが、管理人@PC-KEIBAは「TSV」を強くオススメします。データにカンマが含まれ、プログラムが予期しない動作をする可能性はあっても、データにタブ文字が必要で使われることは99.9%無いからです。
データファイルの作り方
では本当に簡単にですが「A5:SQL Mk-2」を使った、具体的なデータファイルの作り方を紹介します。PC-KEIBA Databaseの「Pythonデータ分析」で出来るデータ分析は「重回帰分析」です。
まず、目的変数を決めましょう。その次に、この項目は目的変数に影響があるんじゃないか?という仮説を立てて説明変数を設計します。例えば、次のような内容でダートのスプリント戦を分析してみます。
■集計条件
- JRA 2020年
- ダート1400m以下
- 異常区分コード = ‘0’ (異常なし)
- 前走 出走頭数 >= 0 (0除算を防止)
※レコード数は9991件になりました。
■目的変数
- 確定着順(相対値)
■説明変数
- 馬体重(相対値)
- 単勝人気順(相対値)
- マイニング予想順位(相対値)
- レース間隔(日数)
- 前走 確定着順(相対値)
- 前走 3コーナーでの順位(相対値)
- 前走 単勝人気順(相対値)
- 前走 後3ハロンタイム(相対値)
- 前走 タイム差
※相対値 = 1 - 順位 / 出走頭数ここでいう相対値とは。例えば、8頭立ての8位と18頭立ての8位は同じ8位でも価値がまったく違います。最下位は0に、1位は多頭数ほど重みが付くように、このような計算式を使いました。
そして、ここまでの内容で設計した目的変数と説明変数の「表」を出力するSQLを書いて「A5:SQL Mk-2」で実行します。目的変数は列の先頭にしておくと何かと便利です。その検索結果をシートの上にある「TSV」ボタンでエクスポート(出力)します。出力する場所は覚えやすい、適当な場所でよいです。
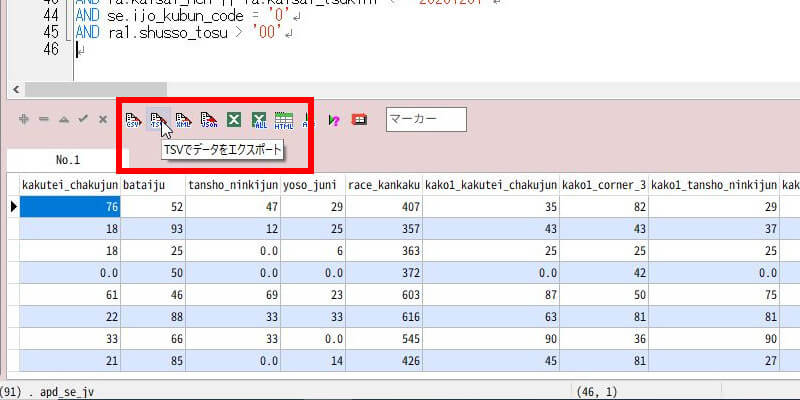
ここまでの内容で作成したデータファイル(TSV形式)のサンプルです。「Pythonデータ分析」画面のテストに使ってください。→ PythonSampleTsv.zip
「データファイルの作り方」は以上です。
この記事のデータ作成に使用したSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
