
このカテゴリーでは競馬予想プログラミング以外でも役に立つ、PostgreSQLの汎用的な技術について解説します。
構文
CREATE INDEX インデックス名 ON テーブル名 (列名1 [, 列名2])インデックスにも色んな種類がありますが、これ以外はほぼ使わんっていう基本の構文だけ書いときます。とりあえずこれだけ知ってたらOKです。
複数の列を使う「複合インデックス」を作りたい場合は、列名1の後に列名2、列名3と、列名をカンマで区切って続けます。インデックス名は自由ですが、分かりやすく管理しやすいようにパターン化するべきです。PC-KEIBA Databaseでは次のパターンで統一しています。
インデックス名の規則
テーブル名+_idx+番号
例えば、馬毎レース情報テーブルに「血統登録番号」のインデックスを作る場合は次のように書きます。
CREATE INDEX jvd_se_idx2 ON jvd_se (ketto_toroku_bango)上記のインデックスはインストール時にソフトが自動的に作成しているのでユーザーが新たに作る必要はありません。この記事の、わかりやすい例として採用しています。
目次
ここから先は「インデックスとはなんぞや?」という人を対象にした内容です。知ってる人は読み飛ばしてください。バリバリのSQLチューニングとかはこの限りじゃないのでマスターしたつもりにならないようご注意ください。
インデックスとは
目的のレコードを効率よく検索するためのデータベースオブジェクトです。インデックスを作る目的は検索処理の高速化です。主キー(プライマリキー)もインデックスの仲間です。
データベースの世界で「レコード」とは、行単位のデータを指します。
インデックスの仕組み
インデックスを作ると、なぜ検索が速くなるのか?その仕組みを説明します。
インデックスの仕組みはデータベース製品によって細かくは異なります。ここでは、わかりやすい一般的な仕組みで説明します。
インデックスとは、レコードを保存してあるテーブルのファイルとは物理的に別のファイルです。そのインデックスは、作るときに決めた列を昇順、例えば、
- 数値の列は 1, 1, 2, 3, 3, 4, 5…
- 文字の列は a, b, b, b, c, d, e…
のような順番にキレイに並べて列の値を保存してます。もっと具体的には次のようなイメージです。血統登録番号がインデックスなら中身はこんな感じになってます。

「複合インデックス」も同じで、組み合わせた列の昇順で並べてます。レースを一意に表す組み合わせ(レース詳細テーブルの主キー)はこんな感じです。各列とその並び順に注目してください。年またぎのレース一覧です。
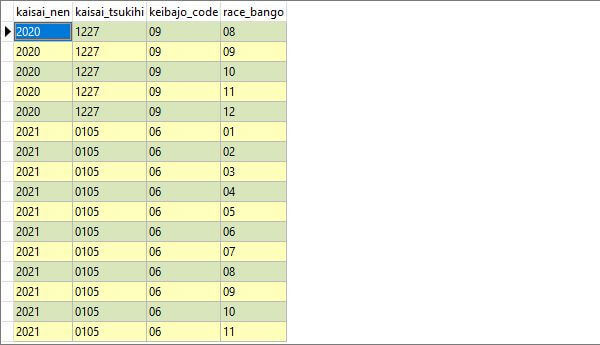
このインデックスのファイルには更に、それぞれのレコードがデータベース内の、どの位置に保存してあるのかを表す情報を保存してます。これは辞典の索引をイメージしてください。「INDEX」を和訳すると「索引」だからそのまんまですね。
この、レコードの並び順が保証されたインデックスを使って目的のレコードの位置情報だけが取得できれば、並び順が決まってないテーブルを全件探すよりも圧倒的に速いというわけです。もしも辞典の単語がバラバラの順番で載ってたら、探すのにメチャクチャ時間かかるでしょ?(笑)
じゃあ、インデックス作りまくればイイじゃん!と思ってしまいますが、残念ながらそうはいきません。
インデックスのデメリット
インデックスを作りすぎるとレコードの新規登録と更新のとき、読み書きすべきファイルが増えてコストが高くなります。つまり、更新処理の速度が落ちるということです。データベースの世界で検索と更新の処理速度はトレードオフです。
なので、本当に必要で意味のあるインデックスだけ作ってください。
インデックスを作るべきパターン
インデックスを作るべきパターンは次の4つです。
- レコード数が多いテーブルの検索
- よく使う検索条件がある
- カーディナリティが高い列
- 目的の値が偏っている列
レコード数が多いテーブルの検索
テーブルのレコード数が少ない場合、インデックスは不要です。オプティマイザにも無視されます。理由は、わざわざインデックスで位置情報を調べるよりも、テーブル全件を直接探したほうが速いからです。言い換えれば、ファイルを2回読むより1回だけのほうが効率的だからです。
「オプティマイザ」とは、SQLを実行するとき、どうすれば最速で目的のレコードを得ることができるか?データベース内で実行計画をたてるプログラムです。
よく使う検索条件がある
レコード数が多いことに加えて、検索条件としてよく使う列や組み合わせがある場合にインデックスの作成を検討します。
テストや一時的な検索処理に対しては時間がかかってもガマンする。または一時的にインデックスを作って、使い終わったらすぐに削除するのも有効です。
カーディナリティが高い列
基本的にカーディナリティが高い列、または複合列の組み合わせに対してのみ、インデックスを作るべきです。
「カーディナリティ」とは、例えばレコード数が多いテーブルの列がほとんど異なる値であれば、その列は「カーディナリティが高い」と言います。逆に0と1だけの2種類しかないフラグのような役割の列は「カーディナリティが低い」と言います。
カーディナリティが低い列でインデックスを作っても意味はありません。やはりこの場合も、インデックスよりテーブルを直接探したほうが効率的だからです。
目的の値が偏っている列
ただし、カーディナリティが低い列でも検索対象の値がテーブルの、全レコードの数%に偏っていればインデックスの効果が期待できます。一般的に10%以下が目安です。
インデックスの設計
インデックスを作っても、検索処理の役に立たないインデックスでは意味がありません。デメリットで話した、更新処理の妨げになるだけです。なので、SQLの実行計画を見てオプティマイザが使ってくれないインデックスは設計を見直すか削除するべきです。
SQL実行計画は「A5:SQL Mk-2」で調べることができます。
インデックスが使える検索パターン
では、オプティマイザは何を基準にインデックスを使うべきか判断するのでしょうか。
先ほど、インデックスは辞典の索引をイメージしてください、と言いました。この例えで説明すると「ことわざ」を辞典で調べるとき、「○○が馬」の○○って何だったっけ?という状況では見出しは役に立ちません。逆に、先頭の「塞翁」が分かってたら「馬」は知らなくても見出しを使って「さいおうがうま」はすぐに見つかるわけです。
この考えからインデックスが使える検索パターンは、
- = 演算子による一致
- >, <, >=, <= 演算子による範囲指定
- IN 句による一致
- LIKE 演算子の前方一致
kaisai_nen = '2021'
kaisai_nen < '2021'
kaisai_nen IN ('2020', '2021')
ketto_toroku_bango LIKE '2016%'が有効となります。逆に使えない検索パターンは、
- NOT, <> 演算子による否定
- LIKE 演算子の部分一致と後方一致
- NULL 値の検索
- 関数か演算子で列の値を編集した検索
kaisai_nen <> '2021'
ketto_toroku_bango LIKE '%04532'
ketto_toroku_bango IS null
to_number(kaisai_nen, '9999') = 2021と、なります。
1つのテーブルにインデックスを複数作っても、1度の検索に使われるインデックスは常に1つです。そのときに最適なインデックスが1テーブルにつき1つだけ選ばれます。PostgreSQLでは実行計画を指示できますが、オプティマイザは優秀なので任せておけばOKです。
複合インデックスは列の順番が重要
ここまでの話から、複合インデックスの設計は列の順番がメチャクチャ重要、と言えます。例えば、レース詳細テーブルの主キーは、
- 開催年
- 開催月日
- 競馬場コード
- レース番号
の順番で設計しています。この順番であればレースを一意に表すという本来の目的以外に、開催年月日だけを検索条件にした検索処理の高速化にも使えて一石二鳥。しかし、この順番が次のように逆だったら、
- レース番号
- 競馬場コード
- 開催月日
- 開催年
この場合は、開催年月日の検索処理には使えません。先ほどの「塞翁が馬」の例えと同じです。レース番号と競馬場コードだけの検索というのも、ほとんど使い道がないと思います。
列はなるべく少なく
複合インデックスの設計を考えるとき、列はなるべく少ないほうが良いです。インデックス(ファイル)のサイズが小さくなるし、インデックスの更新処理も低コストになるからです。
例えば、競走馬マスタ画面の競走成績データを検索するときに使うインデックスは、馬毎レース情報の「血統登録番号」だけで十分。開催年月日の列(並び順)までは不要です。なぜなら、数件のソート処理ならメモリ上でサクッと終わります。目的のレコードをある程度フィルターしたら目的達成です。
この列もインデックスに加えるべきか?と迷うなら、ほとんどは不要でしょう。このあたりは経験か、SQLの実行計画を見ながら試行錯誤してください。


コメント